Neural Networks


input이 affine 계층과 activation 계층을 거치면서 각 층의 output들의 shape이 달라지게 된다. multi classification의 경우 마지막 layer은 class의 개수만큼 output이 출력되도록 만들어야 한다.
neural network를 만들 때 layer의 수, regularization parameter, activation function의 종류 등을 잘 선택해야 한다.
back propagation에서 dL/dW를 어떻게 계산해야 하는가?
loss, model의 종류, activation function의 종류가 바뀜에 따라 dL/dW도 바뀔텐데, 모든 변화를 아우르는 dL/dW를 어떻게 계산하면 좋을까?
=> BackPropagation + Computationla Graph
BackPropagation
2021/02/10 - [밑바닥부터 배우는 딥러닝] - 5장. 오차역전파법<- computational graph 참고

upstream gradient가 흘러들어옴에 따라 downstream gradient를 계산할 때 chain rule을 이용한다. upstream gradient에 곱해지는 중간 생성물을 local gradient라고 한다.

input을 weigh와 함께 softmax로 처리하는 과정을 연속적인 computational graph로 그릴 수 있다.
+) sigmoid local gradient


Patterns in Gradient Flow

copy gate: upstream gradient가 여러개라면, downstream gradient는 upstream들을 그저 합친 것이다.
max gate: 큰 input쪽으로 upstream gradient가 그대로 전해지고, 작은 input은 gradient가 0이 돼서 흐름이 끊긴다.
BackProp Implementation: "Flat" code
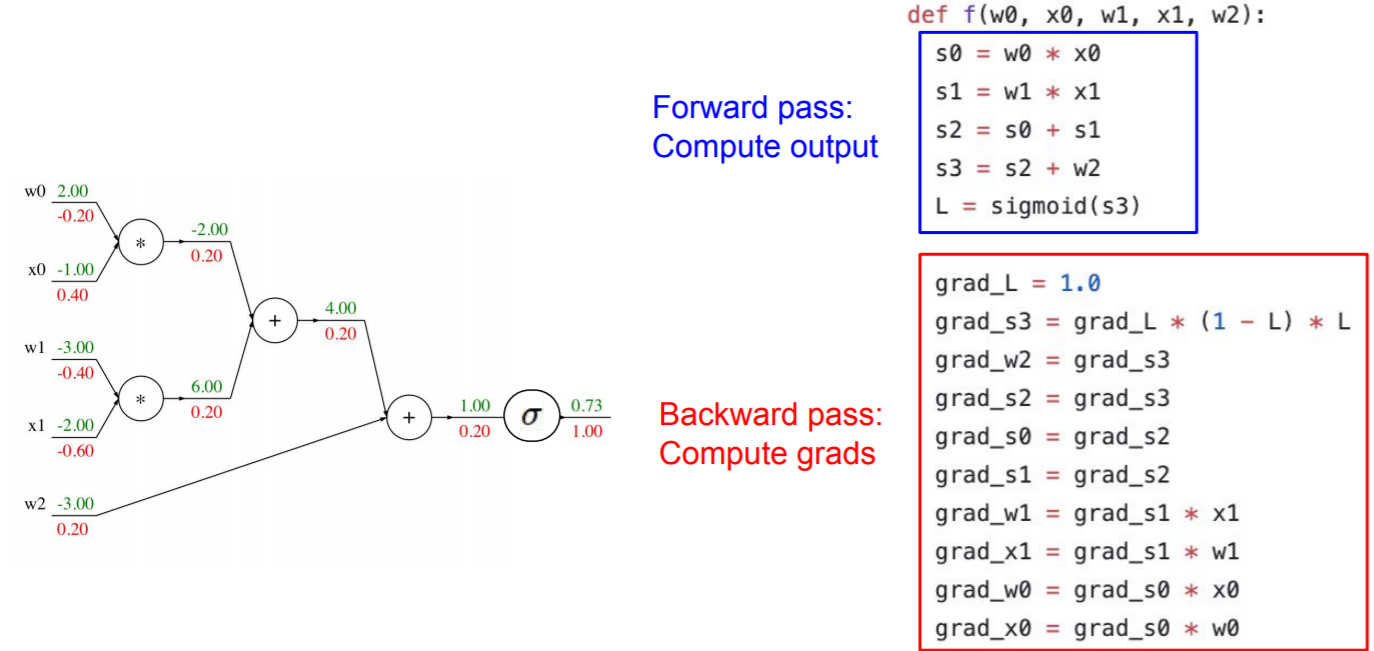
forward pass으로 s0 ~ s3을 거쳐 Loss = 0.73을 계산한다.
Backward pass에서는 순차적으로 grad를 계산한다. d_s3은 softmax에 대한 grad로 upstream gradient에 (1-L)*L을 곱해준다. d_w2, d_s2, d_s0, d_s1는 add node로 upstream grad가 그대로 흘러간다.
d_w1, d_x1, d_w0, d_x0은 mul node로 이전 노드의 상대 값이 upstream grad에 곱해진다.
Vector Derivatives

Backdrop with Vectors

dL/dx, dL/dy, dL/dz는 벡터, dz/dx,dz/dy는 jacobian matrix이다.
dL/dx [ Dx * 1] = dz/dx [ Dx * Dz ] * dL/dz [dZ * 1] 의 행렬 곱으로 나타낼 수 있다.
x와 dL/dx, y와 dL/dy, z와 dL/dz는 shape이 같다.

input x가 ReLu function을 지난다고 할 때 그 때의 gradient를 구하자.

x의 각각의 원소는 0과 max 노드를 통과하게 되고 첫번째, 세번째 원소만 자기 자신이 통과하게 되기 때문에,
upstream gradient인 dL/dz에서 첫번째, 세번째 원소만 유지되고 두번째, 네번째 원소는 0으로 바뀌어야 한다.
dL/dz가 dL/dx이 되기 위해서 곱해져야 하는 dz/dx는 위와 같은 Jacobian matrix가 된다.
Backdrop with Matrices (or Tensors)

x,y가 vector이 아닌 matrix일 때, dz/dx는 곱해졌을 때 행렬의 차원을 유지하기 위해 위와 같은 shape을 가진 Jacobian matrix이다.


dL/dx = dL/dz * dz/dx이다, x의 (n,d)가 바뀌면, y의 (n, )의 모든 원소가 영향을 받아서 y(n,m)에서 m이 모든 원소가 될 수 있어서 ∑를 이용해서 표현할 수 있다. . dL(n,m)/dx(n,d)에서는, dx(n,d)가 바뀌면 w(d,m)만큼 dy(n,m)이 바뀌어서 dL(n,m)/dx(n,d)=w(d,m)으로 쓸 수 있다. 행렬 곱의 차원을 맞추기 위해 dL/dx = dL/dy * w_T라고 쓸 수 있다. 원래 곱셈 노드에서 back prop을 하면 upstream gradient * 상대 원소로 표현되는데, 여기선 차원 수를 맞추기 위해 W에 transpose 해줬다.

dL/dw도 위와 같은 방법으로 위와 같이 쓸 수 있다. 곱셈의 차원을 맞추기 위해 x를 transpose 해줬고, 곱셈 노드의 역전파에서 upstream gradient와 상대 원소를 (transpose 하여) 곱한 것이다.

dq(k)/dW(i,j)는, W(i,j)가 얼만큼 바뀌면 q(k)에 영향을 주는지를 묻는 것이다.
W*x=q이고, W(i,) * x = q(i)이기 때문에 i=k와 같을 때 xj만큼 영향을 줘서, 1(k=i)xj가 된다.
'딥러닝 > cs231n' 카테고리의 다른 글
| 5강. Convolutional Neural Network (4) | 2021.03.12 |
|---|---|
| 3장. Programming: Stochastic Gradient Descent (0) | 2021.03.05 |
| 3장. Multiclass Support Vector Machine : Programming (2) | 2021.02.27 |
| 3장. Loss Functions and Optimization (0) | 2021.02.18 |
| 2강. Image Classification: Programming (0) | 2021.02.17 |



