SVM classifier
1) svm_loss_naive
from builtins import range
import numpy as np
from random import shuffle
from past.builtins import xrange
def svm_loss_naive(W, X, y, reg):
dW = np.zeros(W.shape) # initialize the gradient as zero
num_classes = W.shape[1]
num_train = X.shape[0]
loss = 0.0
for i in range(num_train):
scores = X[i].dot(W)
correct_class_score = scores[y[i]]
for j in range(num_classes):
if j == y[i]:
continue
margin = scores[j] - correct_class_score + 1 # note delta = 1
if margin > 0:
loss += margin
dW[:,y[i]] -= X[i,:]
dW[:,j] += X[i,:]
loss /= num_train
loss += 0.5 * reg * np.sum(W * W)
dW /= num_train
dW += reg*W
return loss, dW(1) Loss function
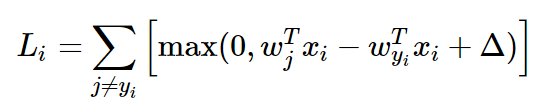
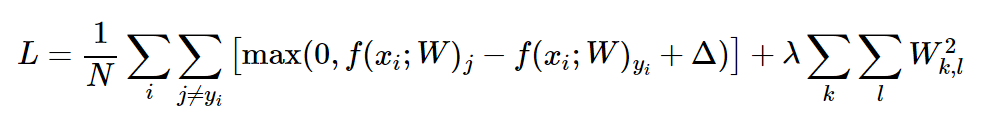
각각의 i번째 example에 대해 scores와 correct_class_score을 표시할 수 있다.
j==yi일 때는 Li에서 계산하지 않기 때문에 pass 하고, s_j - s_yi + 1을 margin으로 둔다.
margin < 0 일때는 Li에 0을 더하는데 딱히 코드가 필요 없다.
margin > 0 일때는 loss에 그만큼의 margin을 더해줘야 한다.
모든 i와 j에 대해 for문으로 Li를 더해주면 ∑(j≠yi)Li가 끝난거고, for문 밖에서 N (=num_train)으로 나누고, regularization term을 더해준다. 여기선 L2 regularization term으로 더해줬는데, 0.5는 후에 미분할 때 제곱에서 2가 곱해질 것이므로 그걸 상쇄하기 위해 곱해준 것이고, np.sum(W*W)에서 W*W는 원소별 곱셈을 의미한다.
(2) Derivatives

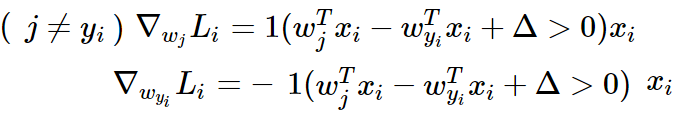
dL/dW에서 dLi/dWj (j ≠ yi), dLi/dWyi는 위와 같이 계산한다.
dLi/dWj (j ≠ yi)은 s_j - s_yi + 1>0이면, 즉 올바른 class로 예측을 했다면 1 * xi를 해주라는 의미이다.
dLi/dWyi은 올바른 class로 예측 했다면 -1 * xi를 해주라는 의미이다.
코드에서 보자면, margin > 0일 때 dLi/dWj은 +xi, dLi/dWyi는 -xi를 해주라는 것과 같고,
dW에서 각 i에 대해 정답에 해당하는 열에서 -X[i,:]를 해줬고, 오답에 해당하는 열에서 +X[i,:]를 해줬다.
loss에서와 마찬가지로, for문을 나와서 N(=num_train)으로 나눠주고 regularization term으로 reg * W를 더해줬다.
2) svm_loss_vectorized
def svm_loss_vectorized(W, X, y, reg):
loss = 0.0
dW = np.zeros(W.shape) # initialize the gradient as zero
num_train = X.shape[0]
scores = X.dot(W)
yi_scores = scores[np.arange(scores.shape[0]),y] # http://stackoverflow.com/a/23435843/459241
margins = np.maximum(0, scores - yi_scores.reshape((num_train,1)) + 1)
margins[np.arange(num_train),y] = 0
loss = np.mean(np.sum(margins, axis=1))
loss += 0.5 * reg * np.sum(W * W)
binary = margins
binary[margins > 0] = 1
row_sum = np.sum(binary, axis=1)
binary[np.arange(num_train), y] = -row_sum.T
dW = np.dot(X.T, binary)
dW /= num_train
dW += reg*W
return loss, dW
(1) Loss Function
scores = X.dot(W)
한번에 score을 계산한다.
yi_scores = scores[np.arange(scores.shape[0], y] : s_yi
np.arange(N) = > array([0, 1, 2, ..., N]
y => array([9, 3, 5, ... ]) (N,)의 정답 layer에 해당하는 값
scores[ array([0, 1, 2, ..., N] , array([9, 3, 5, ... ])] => 0행에는 9열, 1행에는 3열, 2행에는 5열, ... 각 example에 대해 정답 class의 score만을 추출해 오는 코드, yi_scores는 (500,)의 shape을 가짐.
margins = np.maximum(0, scores - yi_scores.reshape((num_train,1)) + 1)
vector은 가끔 shape이 애매할 때가 있어서 yi_scores가 (500,1)의 shape을 확실하게 가지도록 reshape 해줬다.
scores: (500, 10), yi_scores: (500,1), 1: (1,1)이었는데 (500,10)으로 broadcasting 됐다.
np.maximum(0, ~)은, 두 array에서 원소값을 비교하여 큰 원소값으로 대체해준다. 여기서도 0: (1,1)이 (500,10)으로 broadcasting 되어 모든 원소값이 0과 비교된다.
margins[np.arange(num_train),y] = 0
Li = ∑(j ≠ yi) ~ , 더해줄 때 yi 항목을 제외하기 위해 각 example에 대해 정답 class의 score을 0으로 만들어준다.
loss = np.mean(np.sum(margins, axis=1))
loss += 0.5 * reg * np.sum(W * W)
L = (1/N)∑Li에 regularization term을 더해줬다.
(2) derivatives
binary = margins
binary[margins > 0] = 1
margins를 binary로 불러오고, margins > 0인 원소, 즉 j ≠ yi에 대해 옳게 분류한 원소들만 1로 살려둔다.
row_sum = np.sum(binary, axis=1)
binary에 각 행별로 합하면 각 example에서 몇 번 정답이 나왔는지 알 수 있다.
binary[np.arange(num_train), y] = -row_sum.T
각 example에 대해 정답 class의 score에서 정답 횟수만큼 빼준다. 각 example에서 정답 class에는 -(정답횟수)가 될 것.
dLi/dWyi에서 -xi를 해주기 위한 빌드업.
dW = np.dot(X.T, binary)
dLi/dWj은 +xi을 해줘야 한다. j ≠ yi에 대해 정답을 맞춰서 s_j - s_yi + 1 > 0인 s_j는 1로 표현되었을 것이다. 1에 xi가 곱해져서 정답을 맞춘 j 자리에는 +xi가 들어올 것이다.
dLi/dWyi는 -xi을 해줘야 한다. s_yi는 위 코드에 의해 -(정답횟수)가 채워질 것이다. 여기에 xi가 곱해져서 정답을 맞춘 횟수만큼 xi가 빼진다.
'딥러닝 > cs231n' 카테고리의 다른 글
| 3장. Programming: Stochastic Gradient Descent (0) | 2021.03.05 |
|---|---|
| 4장. Neural Networks and Back Propagation (0) | 2021.03.05 |
| 3장. Loss Functions and Optimization (0) | 2021.02.18 |
| 2강. Image Classification: Programming (0) | 2021.02.17 |
| 2강. Image Classification (0) | 2021.02.16 |



