image classification
input 이미지를 여러 카테고리 중 하나의 label로 할당하는 것으로 컴퓨터 비전의 핵심 문제이다.
컴퓨터가 이미지를 분류하기 어려운 이유
- 카메라의 각도, 조명, 이미지의 크기에 따라 pixel이 달라짐
- 물체가 가려지거나 배경색과 비슷해지면 인식이 어려움
- 하나의 대상이 여러 모양을 가진 경우
=>좋은 image classification model은 이러한 variation에 흔들리지 않아야 한다.
Data-driven approach
label을 가진 training set으로 model을 학습하는 알고리즘 [input -> learning -> evaluation]의 과정이 필요하다.
- input: n개의 training example이 k개의 class를 가지고 있고 training set으로
- learning: train set으로 classifier 학습
- evaluation: classifier로 test set을 검정
Nearest Neighbor Classifier
CIFAR-10: image classification 예제로, 60000개의 training set, 10000개의 test set으로 이루어졌고 아래와 같은 10개의 class를 가지고 있다.

Nearest Neighbor Classifier
하나의 test 이미지를 50000개의 train 이미지와 비교하여 가장 가까운 train 이미지의 label로 예측하는 model

이미지간 거리를 측정하는 방법
하나의 이미지 예시는 32*32*3개의 pixel을 가지고 있다. nearest neighbor classifier은 이미지의 pixel끼리 비교하여 가까운 이미지를 찾아야 하는데, '가까운 이미지'라는 기준을 어떻게 세울 것인가?
(1) L1 distance

하나의 test example의 pixel 요소들을 training example의 pixel 요소들과 빼서 절댓값을 씌워서 합산한다.

(Xtr, Ytr), (Xte, Yte) = cifar10.load_data()
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) # Xtr_rows becomes 50000 x 3072
Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) # Xte_rows becomes 10000 x 3072train set과 test seet을 불러온 후에 X train과 X test의 각 example을 vector 형태로 만들어준다. 하나의 행에 example의 pixel값이 모두 담기도록 reshape 해준다.
import numpy as np
class NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
num_test = X.shape[0]
# lets make sure that the output type matches the input type
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# loop over all test rows
for i in range(num_test):
# find the nearest training image to the i'th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1) #self.Xtr: test image, X[i,:]: i번째 train set
min_index = np.argmin(distances) # get the index with smallest distance
Ypred[i] = self.ytr[min_index] # predict the label of the nearest example
return Ypredtrain에서 X train과 Y train의 정보를 기억한다.
predict에서 train의 정보를 가지고 X test의 label 값을 predict 하여 이를 Ypred 벡터에 넣어줄 것이다.

L1 distance로 각 원소별로 빼서 절댓값을 취해준 후 np.sum(axis=1)로 각 행별로 합해준다.
np.argmin()으로 행들의 최솟값에 해당하는 label을 min_index로 넣어주고 ytr[min_index]의 값을 Ypred의 i번째 원소에 넣어준다.
nn = NearestNeighbor() # create a Nearest Neighbor classifier class
nn.train(Xtr_rows, Ytr) # train the classifier on the training images and labels
Yte_predict = nn.predict(Xte_rows) # predict labels on the test images
# and now print the classification accuracy, which is the average number
# of examples that are correctly predicted (i.e. label matches)
print 'accuracy: %f' % ( np.mean(Yte_predict == Yte) )NearestNeighboor() classifier을 만들고 X train을 reshape 한 Xtr_rows와 Ytr으로 train 한다.
이렇게 train 한 nn으로 Xte_rows를 predict 한다.
Yte_predict와 Yte 사이의 정확도를 계산한다.
이 결과 38.6%의 정확도를 얻었다.
(2) L2 distance
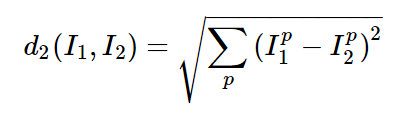
두 벡터 사이의 유클리디안 거리를 측정하는 방법이다.
distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1))Xtr과 X의 i행을 빼고 제곱한 뒤 행별로 더하여 더한 값을 루트 씌워준다.
이렇게 L2 dist를 계산하여 nn으로 accuracy를 계산하면 35.4%의 정확도가 나온다.
| L1 distance | L2 distance |
 |
 |
 |
 |
| - 좌표 시스템이 변하면 L1도 변한다. (좌표계 의존적) - feature들간 개별적 의미를 가지면 L1을 사용하자 |
- feature들간 의미를 잘 알지 못하면 L2를 사용하자 |
| L1과 L2는 문제 의존적이기 때문에 데이터에 모두 적용해보고 성능이 좋은 것을 선택하자. (hyperparameter tuning) | |
Nearest Neighbor 방법의 단점
- train time <<< test time 이라는 점
- 하나의 test example을 모든 train example과 비교해야 해서 시간이 오래 걸린다.
- train set으로 model을 만드는 과정이 오래 걸리더라도 test set을 predict 하는 시간은 적게 걸려야 한다.
K-nearest Neighbor Classifier

test image와 가까운 k개의 train example을 찾아서 k개끼리 투표로 label을 결정한다. k가 높을 수록 decision boundary가 smooth 하다.
5-NN classifier에서 메꿔지지 않은 흰색 영역은 knn이 다수결로 label을 정할 수 없는 경우에 관한 것이다.
Validation sets for Hyperparameter tuning
knn을 할 때 k와 distance metrics를 선택해야 하고 이를 hyperparameter라고 한다. 이 hyperparameter를 어떤 방법으로 결정하면 좋을까?
(1) validation set

train set으로 학습을 진행하여 model을 만들고, model을 validation set으로 검증하여 좋은 hyperparameter을 찾고, model의 정확도 검정을 위해 test set을 마지막에 한번만 사용한다. => test set을 마지막에 한 번만 사용함으로써 model의 generalization을 보여줄 수 있다.
# assume we have Xtr_rows, Ytr, Xte_rows, Yte as before
# recall Xtr_rows is 50,000 x 3072 matrix
Xval_rows = Xtr_rows[:1000, :] # take first 1000 for validation
Yval = Ytr[:1000]
Xtr_rows = Xtr_rows[1000:, :] # keep last 49,000 for train
Ytr = Ytr[1000:]
# find hyperparameters that work best on the validation set
validation_accuracies = []
for k in [1, 3, 5, 10, 20, 50, 100]:
# use a particular value of k and evaluation on validation data
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
# here we assume a modified NearestNeighbor class that can take a k as input
Yval_predict = nn.predict(Xval_rows, k = k)
acc = np.mean(Yval_predict == Yval)
print 'accuracy: %f' % (acc,)
# keep track of what works on the validation set
validation_accuracies.append((k, acc))50000개의 Xtr_rows 데이터를 1000개의 validation set과 49000개의 training set으로 다시 나누었다.
validation set에서 k를 결정할 것이다.
각각의 k에 대해 Xtrain,Ytrain을 k-nearest neighbor 방법으로 학습하고 Xval에서 model의 정확도를 측정할 것이다.
모든 k에 대해 학습과 예측이 완료되면, validation set에서 정확도가 가장 높게 나온 k를 선택할 것이다.
(2) cross validation

data set이 아주 작은 경우에 cross-validation 방법을 사용할 수도 있다. train set을 k개의 fold로 나눈 뒤, 하나의 fold를 validation set으로, 나머지 fold들을 train set으로 사용한다. validation set을 바꿔가면서 반복 수행하여 적정한 hyper parameter을 찾고고 test set은 마지막으로 한 번 성능 검정을 위해 사용한다.
test set의 accuracy가 model의 성능을 대표할 수 있다는 것은 모든 dataset이 iid 가정을 따라 추출되었을 때를 전제한다.

cross validation 방법을 이용할 때 validation fold별로 분산을 같이 계산할 수 있다.
fold=5로 설정하면 각각의 validation fold별로 model의 accuracy를 계산할 수 있어서 총 5개의 accuracy가 계산된다. 위 표는 k를 다양하게 설정했을 때 각 fold별로 accuracy의 분산도 표시했다. 실선은 accuracy의 평균을 이은 것이다.
위 데이터에서는 fold=5일 때 k=7로 설정해야 성능이 가장 높은 것을 확인할 수 있다.
fold를 더 키우면 curve가 더 smooth 해질 것이다.
KNN의 단점
① test time이 굉장히 오래 걸린다.
② L1, L2 distance의 설명력이 좋지 않다.

KNN에 사용하는 L1,L2 distance는 pixel 의존적인 방법으로, 높은 차원의 데이터를 픽셀 의존적인 방법으로 차이를 계산하는 것은 직관적이지 않다. original 이미지를 다른 방법으로 변형시킨 후 original 이미지와 L2 distance를 측정했더니 모두 비슷하게 나왔다. 즉, L1, L2 distance가 이미지의 유사도를 측정하는 데 좋은 방법이 아니다.
③ 방대한 양의 dataset이 필요하다.

- 차원의 저주: 데이터의 차원이 높아짐에 따라 그 공간들을 조밀하게 덮기 위해 필요한 데이터의 수가 많아지는데, 차원의 수가 높아지면서 필요한 데이터의 수가 기하급수적으로 늘어난다.
Linear Classification

D: feature의 수, K: class의 수
(CIFAR-10에서는 D=32*32*3=3072, K=10이었다.)
위를 만족하는 cost function f를 찾아야 한다.

xi: 각 training set의 example이 flatten 된 형태 [D*1]
W: [K*D] weight (parameter), W의 각 행이 1~K class에 대한 classifier라고 할 수 있다.
b: [K*1] bias vector(parameter), xi에 영향을 주지 않는다.

하나의 이미지가 4개의 pixel만을 가지고 구분하려는 class는 cat, dog, ship으로 3가지라고 하자. xi는 pixel을 열벡터로 flatten 시킨 것이고 W*xi+b를 계산했을 때 이미지가 cat, dog, ship이 될 score가 나타난다.
=> Parametric Approach (매개변수적 접근): parameter인 W,b로 X에 대한 predict가 가능해진다.
Analogy of images as high-dimensional points
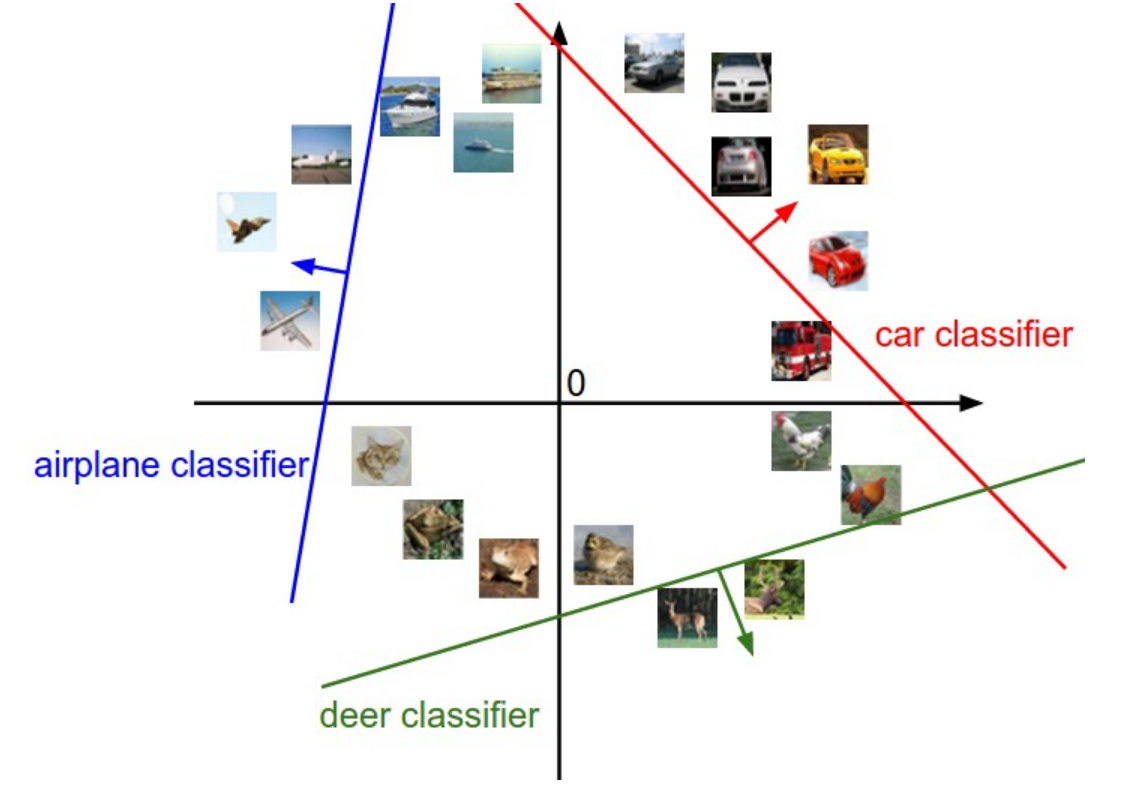
이미지를 공간에서 점으로 나타내보자. 각 이미지가 2개의 pixel (D=2)만으로 축소한다고 해보자.
f(W,x,b)=Wx+b로, W의 기울기와 b의 절편을 가지는 일차함수들을 만든다고 생각해보자. 직선을 경계로 한 방향엔 특정 class에 속하는 x가 들어있다고 할 수 있다. linear하게 x들을 분류할 수 있도록 W,b를 잘 설정하여 classifier을 만들 수 있을 것이다.

각 class에 해당되는 행벡터를 시각화 한 것이다.
ship template은 파란색 pixel을 많이 포함하고 있고, input으로 파란색 이미지가 오면 높은 점수를 부여할 것이다.
horse template은 머리를 두 개 가지고 있다. linear classifier가 하나의 template에 두 모드의 horse를 합친 것이다.
car template은 여러 방향에서 본 car을 합친 것이다. CIFAR-10 데이터셋에 빨간 차가 많았던 것 같다.
새로운 색깔의 차를 input으로 넣으면 car template은 잘 분류하지 못할 것이다.
=> 카테고리마다 하나의 결과밖에 내지 못한다는 한계가 있다.
Linear Classifier을 적용하기 어려운 경우
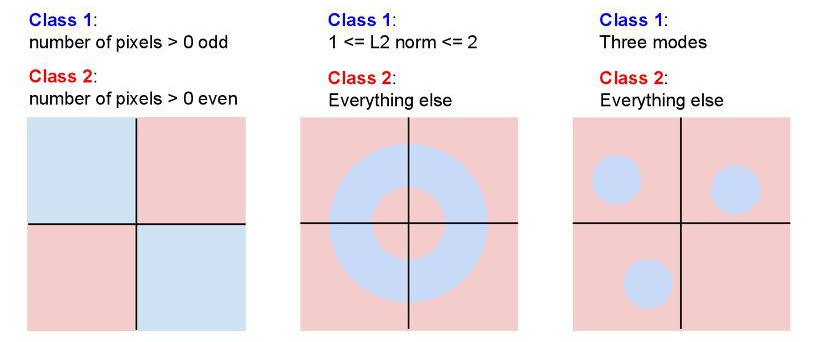
위의 세가지 경우처럼 linear 한 classifier로 classification을 수행할 수 없는 경우가 있을 것이다.
Bias trick

xi를 늘려서 b와 W를 하나로 합쳐서 f(xi,W,b)=W*xi+b가 아닌 f(xi,W)=W*xi로 한 번에 쓸 수 있다.
xi의 맨 마지막 요소를 1로 추가하고, W의 맨 오른쪽 열에 b를 붙이면 W*xi에 b*1이 더해진 꼴이라고 볼 수 있다.
Image data Preprocessing
각 pixel에 평균을 빼서 pixel의 range를 [0,255]가 아닌 [-127,127]로 만들어서 평균을 0으로 만들어 줄 수 있다.
이를 max값으로 나눠서 range를 [-1,1]로 바꿔줄 수도 있다.
'딥러닝 > cs231n' 카테고리의 다른 글
| 3장. Programming: Stochastic Gradient Descent (0) | 2021.03.05 |
|---|---|
| 4장. Neural Networks and Back Propagation (0) | 2021.03.05 |
| 3장. Multiclass Support Vector Machine : Programming (2) | 2021.02.27 |
| 3장. Loss Functions and Optimization (0) | 2021.02.18 |
| 2강. Image Classification: Programming (0) | 2021.02.17 |



