분석 패널
- 화면을 만든 후에 +a를 첨가할 수 있는 기능을 제공한다.
- 데이터에 스토리를 만들거나 컨텍스트를 부여하여, 깊은 수준의 분석이 가능하다.
* 바 차트에서의 상수 라인과 평균 라인
상수 라인
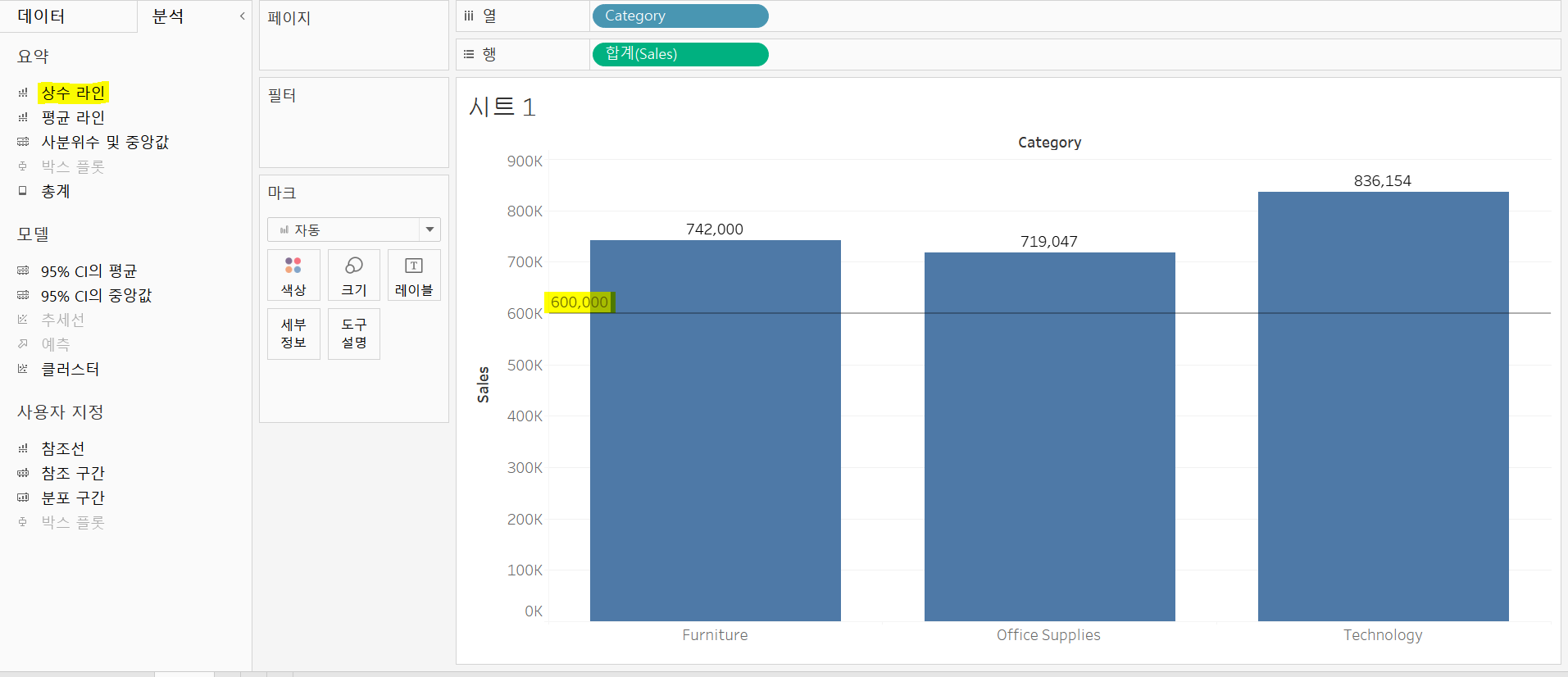
'상수 라인'은 사용자가 지정한 특정 값을 화면에 표시할 수 있다.
카테고리 별 sales를 알기 위해 선반에 올려놓고 분석 탭에서 상수라인을 시트 안에 끌고 오면 상수를 설정할 수 있고 그 상수가 시트 안에서 선으로 표시된다.
각 카테고리에서의 sales 값이 600K보다 높은지, 낮은지를 쉽게 확인할 수 있다.
평균 라인
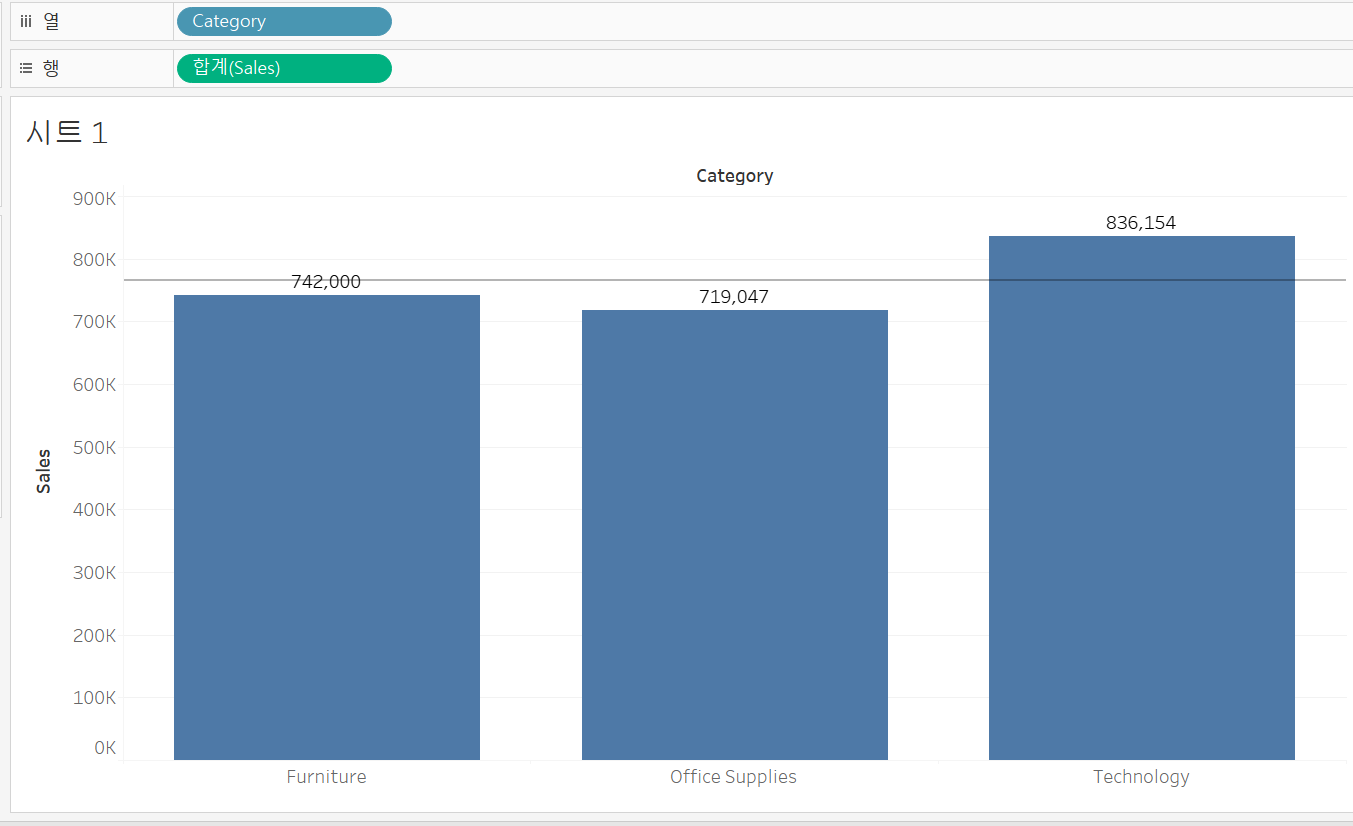
상수 라인에서는 특정 값을 설정해야 했지만 평균 라인에서는 현재 VLOD에 올라간 값들에 대한 평균을 나타낸다.
평균 라인이 보이는 형식을 세개 중 하나로 지정할 수 있다.
- 셀: 각 카테고리별로
- 테이블: 화면 전체에
- 패널: 셀과 테이블 중간
아래는 '테이블' 방식으로 평균 라인을 내 준 것이다.
* 레이블 추가하기
평균 라인 우클릭>편집>레이블 '값'으로 라인에 값을 추가해줄 수 있다.
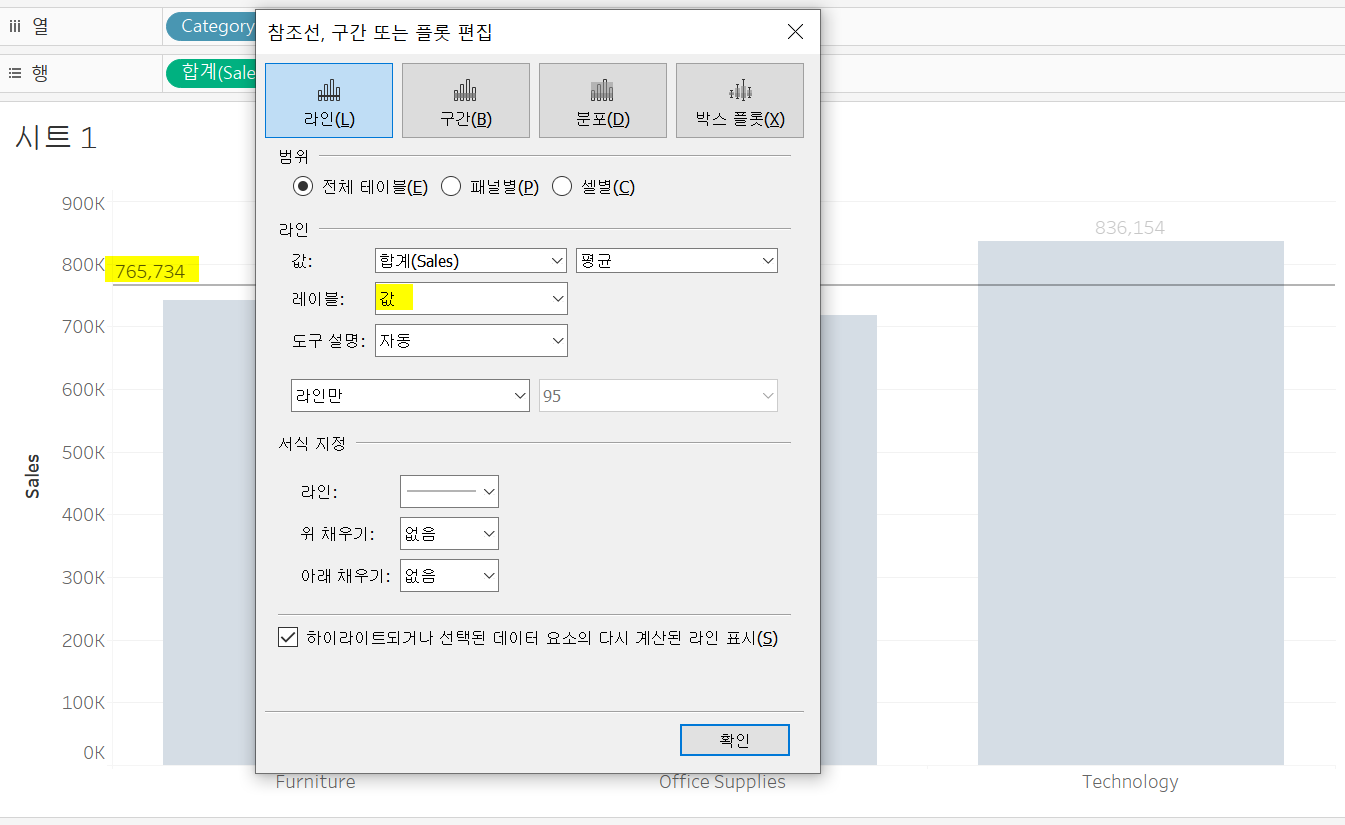
사용자에게 이 라인이 평균 라인임을 강조하기 위해 레이블을 '평균 = (값)' 형식으로 지정해줄 수 있다.
평균 라인 우클릭> 편집>레이블: 사용자 지정, 우측의 오른쪽 화살표로 <계산>=<값> 추가해주기
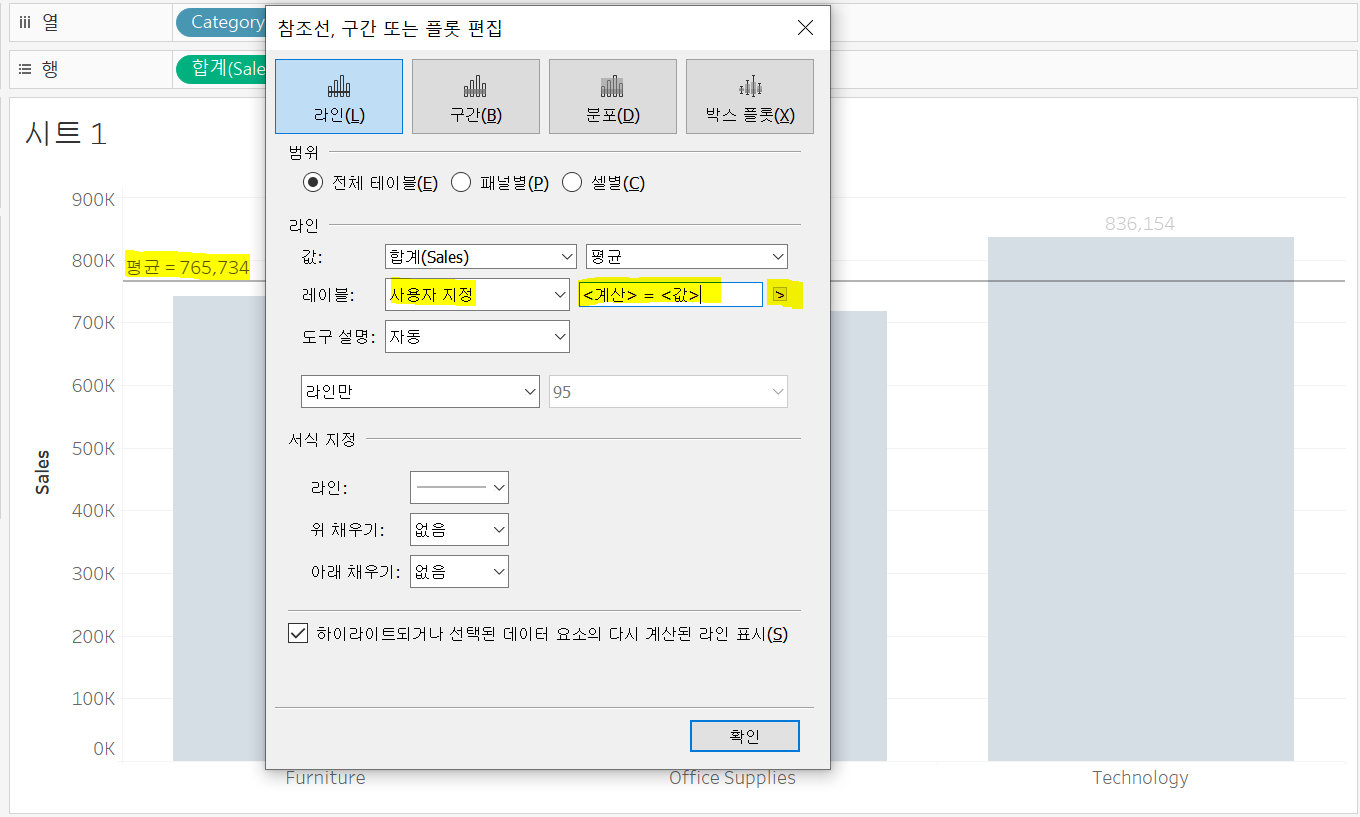
한 화면에서 평균 라인은 1개, 상수 라인은 몇개든 계속 포함 가능하다.
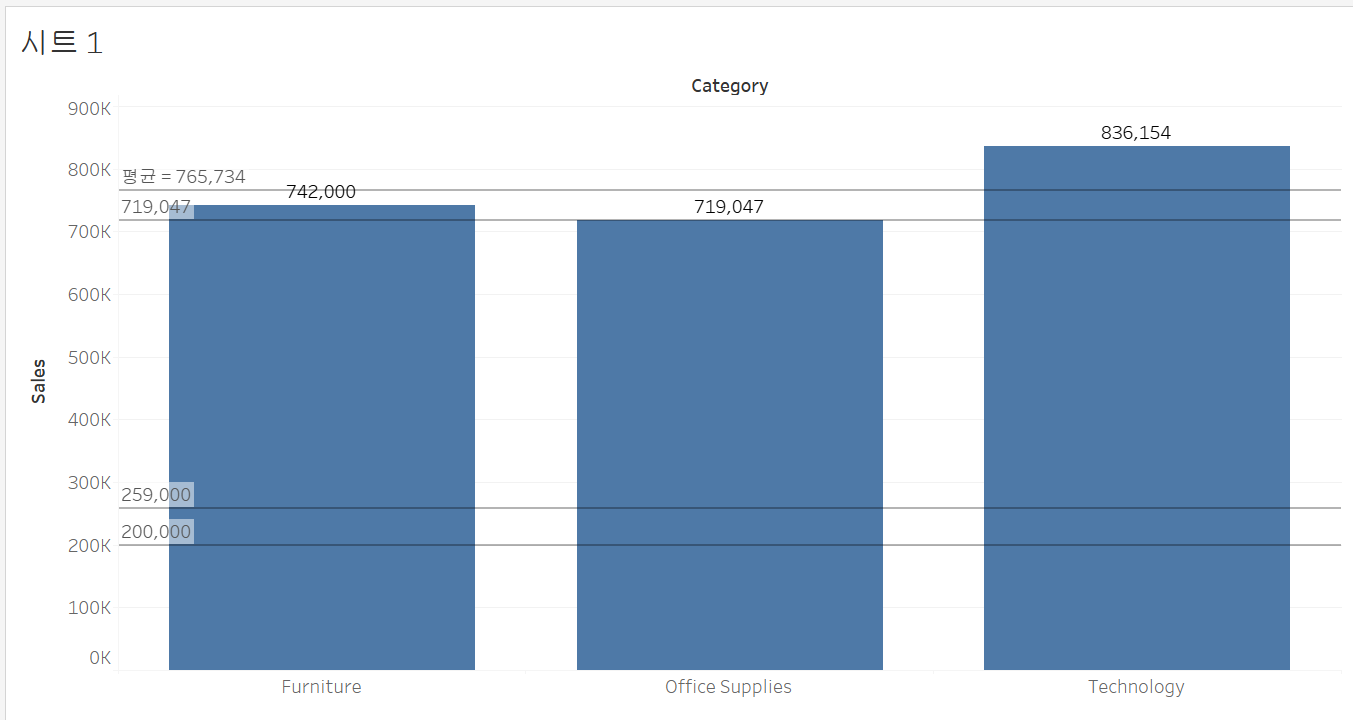
열선반에 sub category를 추가로 올려서 데이터를 분기하겠다. 분기를 했기 때문에 subcategory 별 평균 값이 76만에서 13만으로 달라졌다. 상수 라인은 VLOD에 관계 없이 일정하지만, 평균 라인은 VLOD에 따라 변한다.

* 라인 차트에서의 상수 라인과 평균 라인
열선반에 order date의 연속형 월을, 행선반에 sales를 둬서 라인 차트를 만들고 분석 탭에서 평균 라인을 추가했다.
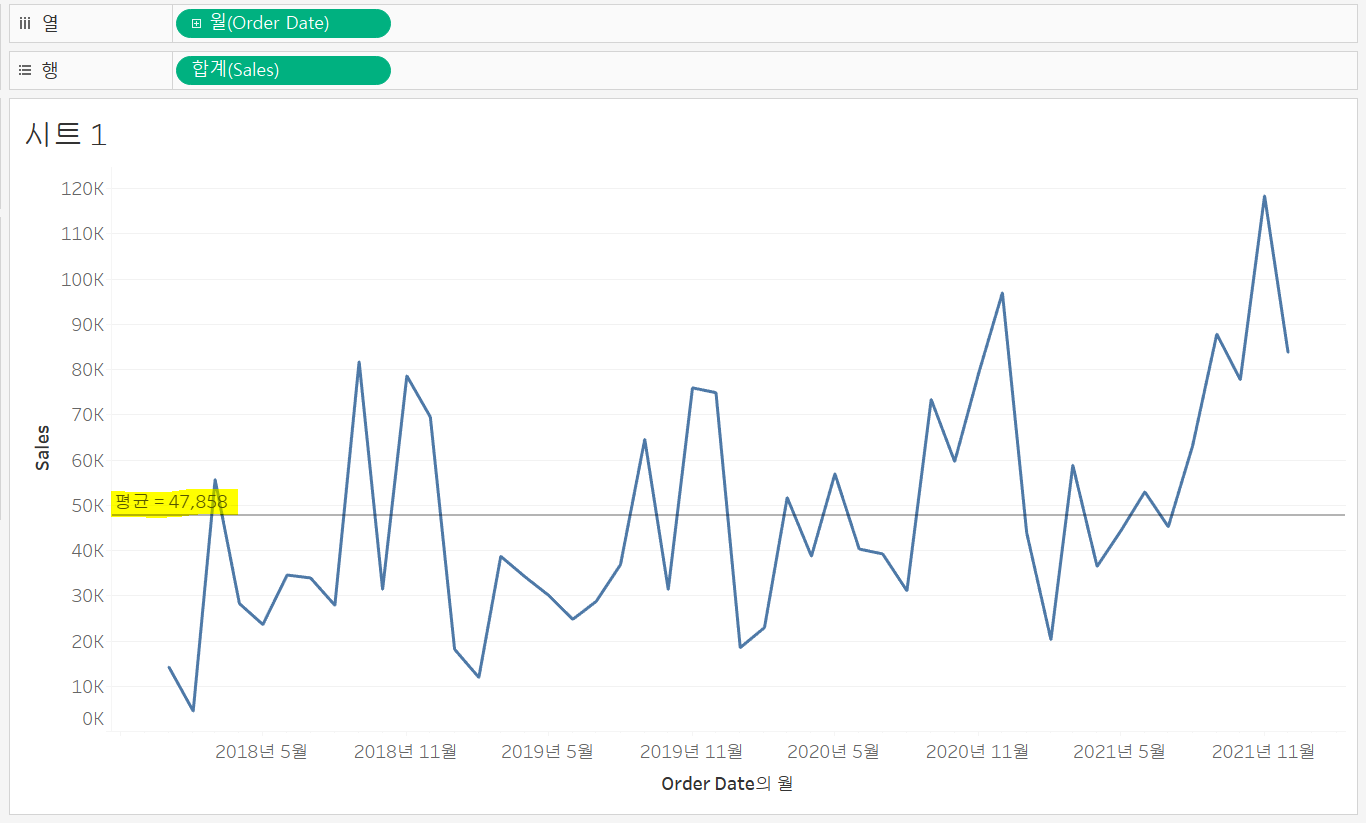
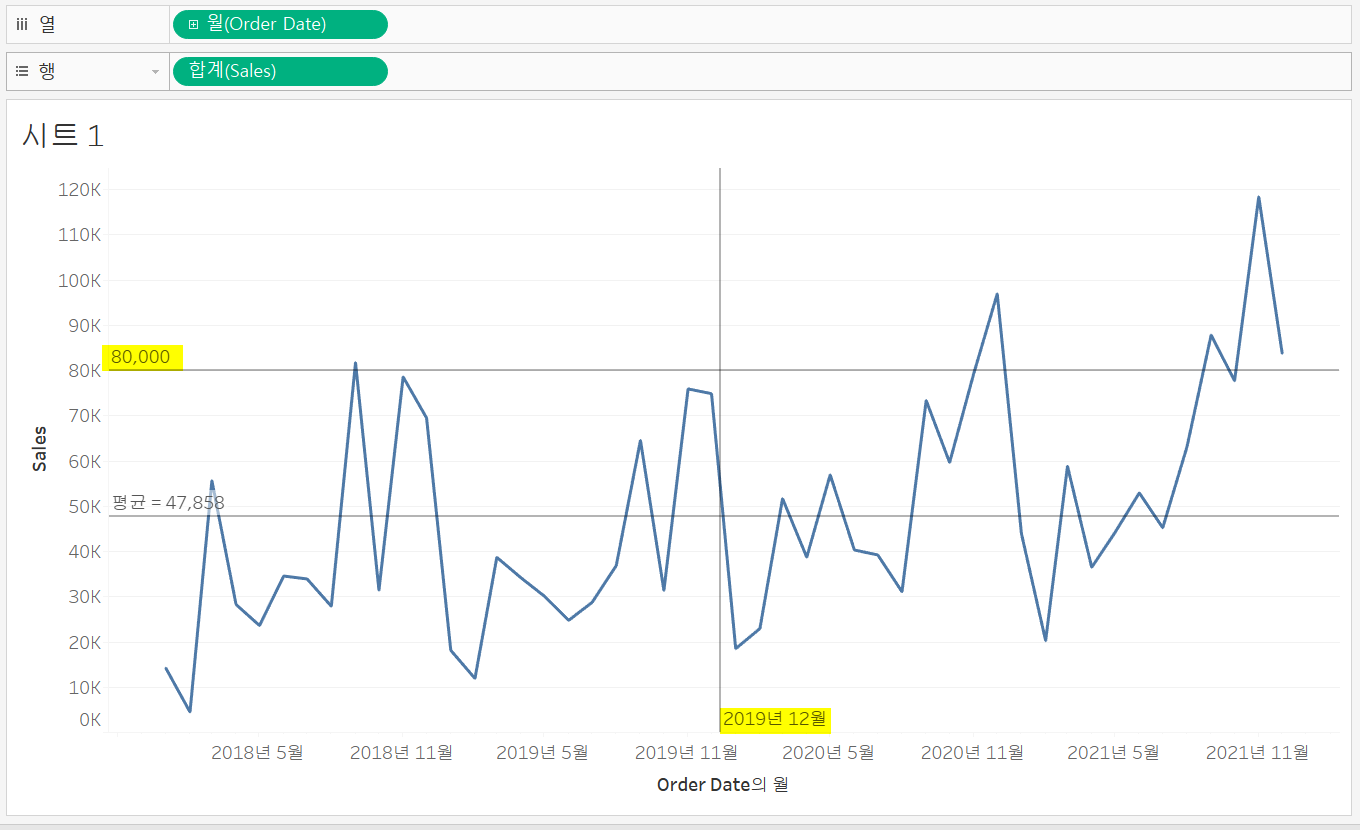
라인 차트에서 상수 라인은 열선반, 행선반 각각의 변수에 대해 추가할 수 있다.
sales에 80000으로 추가해서 가로선이 그어졌고, order date에 2019년 12월으로 추가해서 세로선이 그어졌다.
* 상수 라인/평균 라인과 스토리 텔링
| 상수 라인/평균 라인이 없을 때 | 상수 라인/평균 라인이 있을 때 |
 |
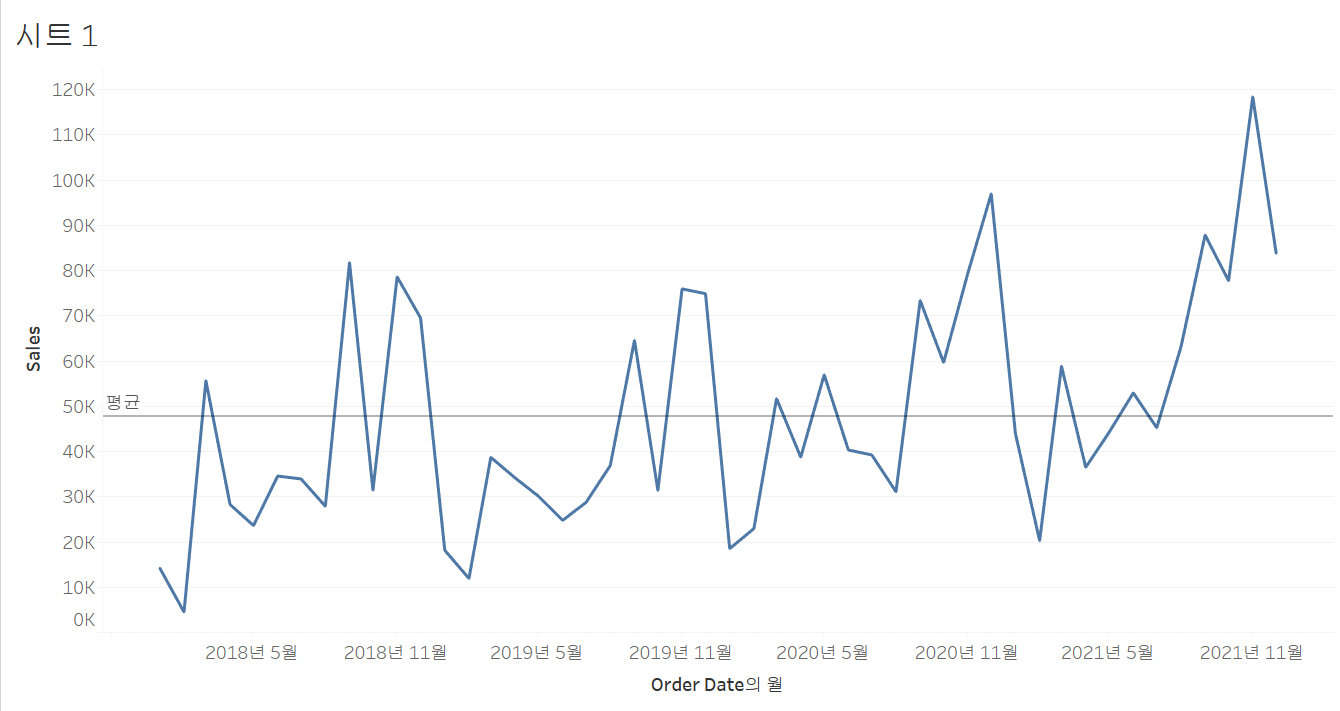 |
| 4년간 매출이 증가 트렌드에 있다. | 4년간 9월, 11월, 12월에 sales가 평균보다 높았다 |
| => 상수 라인/평균 라인으로 화면에 컨텍스트와 스토리를 더할 수 있다. | |
총계
'총계'는 차트보다는 테이블에서 많이 쓴다. region과 category 별 sales의 합계를 확인하기 위한 테이블을 만들었다.
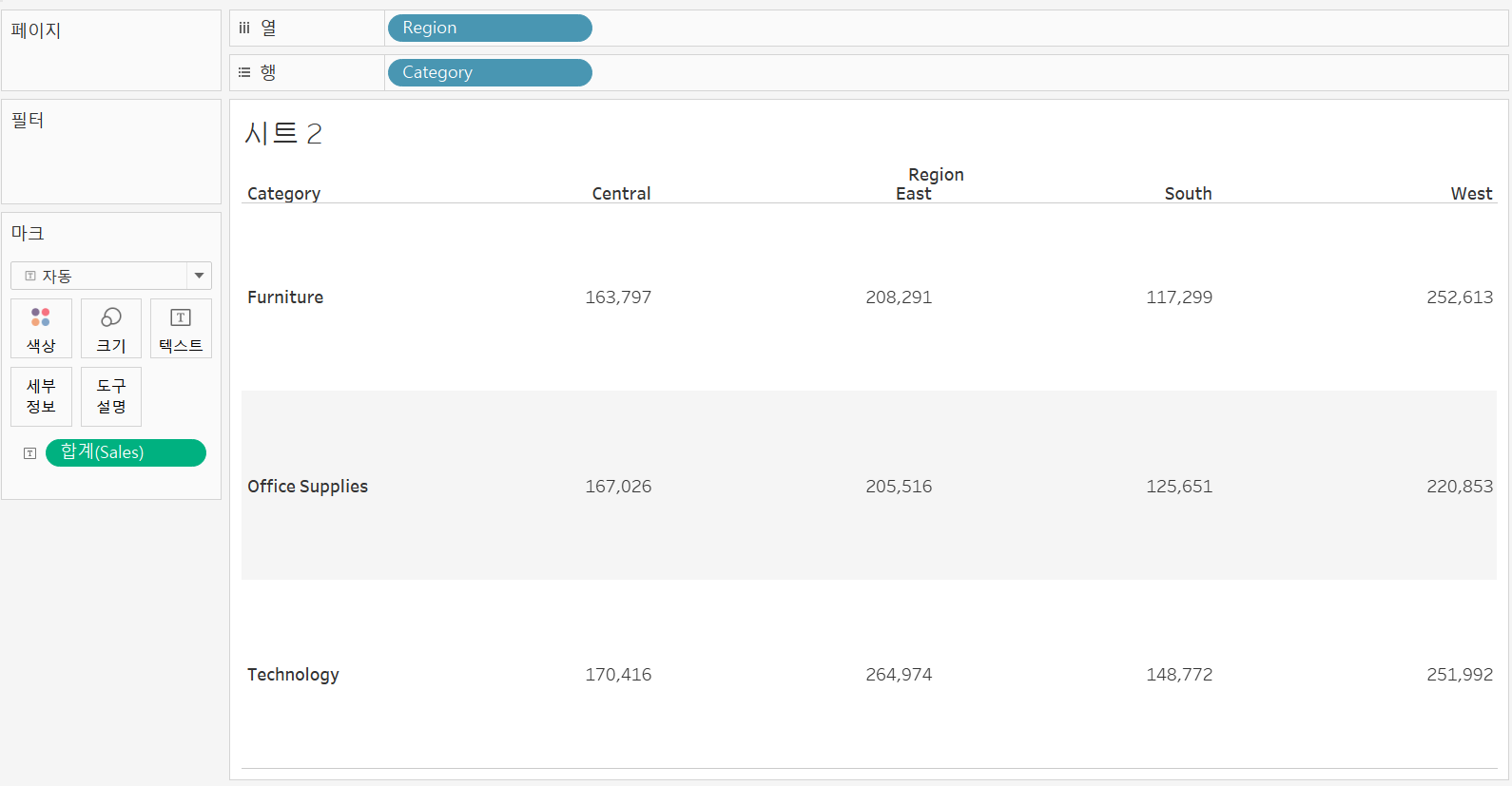
분석 탭에서 '총계'를 테이블 안으로 끌어 놓으면 '소계', '열 총합계', '행 총합계'를 선택할 수 있다.
세로로 나타나는 것이 '행 총합계', 가로로 나타나는 것이 '열 총합계'이다.
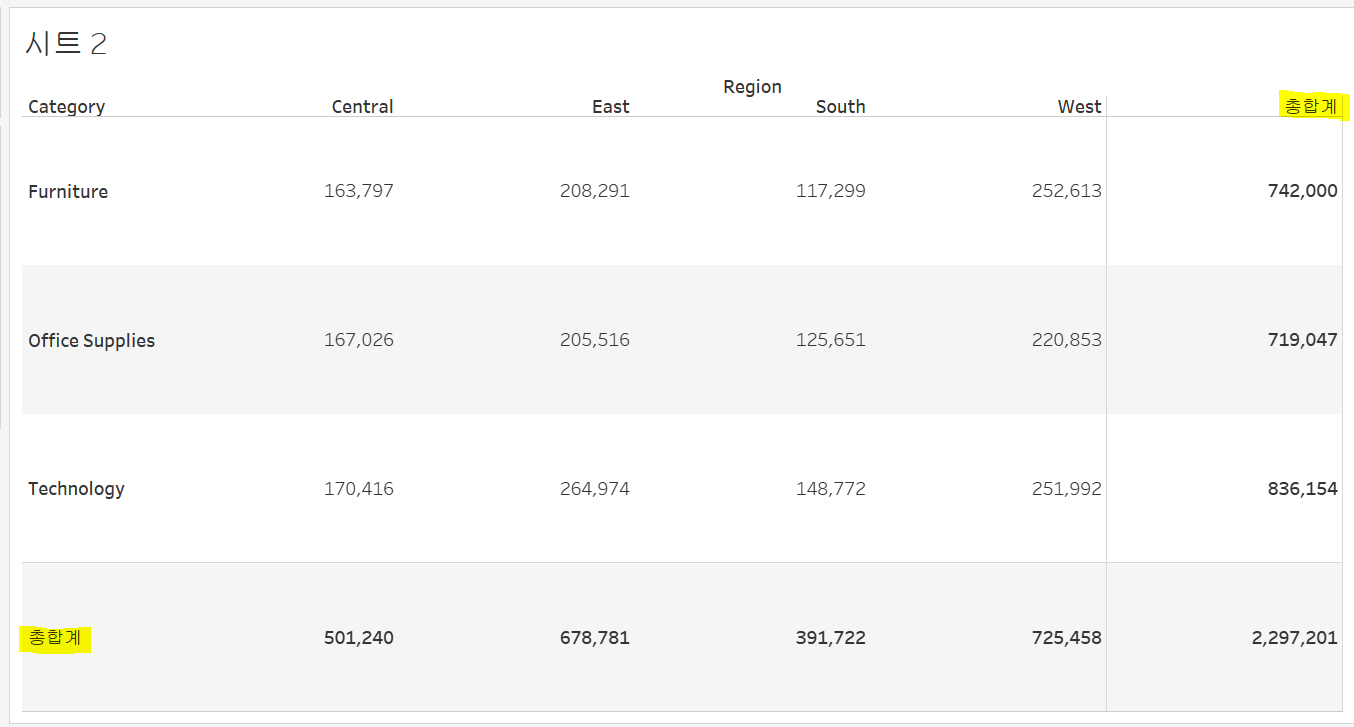
여기서 subcategory로 다시 분기한 후 '총계'에서 '소계'를 선택하여 테이블 안으로 끌어 놓으면 category 별 subcategory의 소계도 나타낼 수 있다.

열의 총합계를 위에서 확인하기 위해 분석>총계>열총계를 맨 위로를 선택할 수 있다.

추세선
할인율이 높아질 수록 수익성이 떨어진다는 가설을 검증하기 위해 discount를 열선반에, profit을 행선반에, (profit ratio를 올려야 하는데 엑셀 파일에는 없어서 profit으로 대체함) product name을 시트 위에 올렸다.
정확한 분석을 위해, discount가 0인 점들은 우클릭하여 제외했다.

분석 탭>추세선>선형을 선택해서 선형 추세선을 그렸다.

선형 이외에도 로그/지수/다항식/거듭제곱 등의 추세선을 그릴 수 있다. 다양한 추세선을 바탕으로 데이터가 단순히 선형 증감이 아니라 어떤 지점을 거친 후에 크게 증감하는지 등 데이터의 추세를 더 잘 파악할 수 있다.
예측
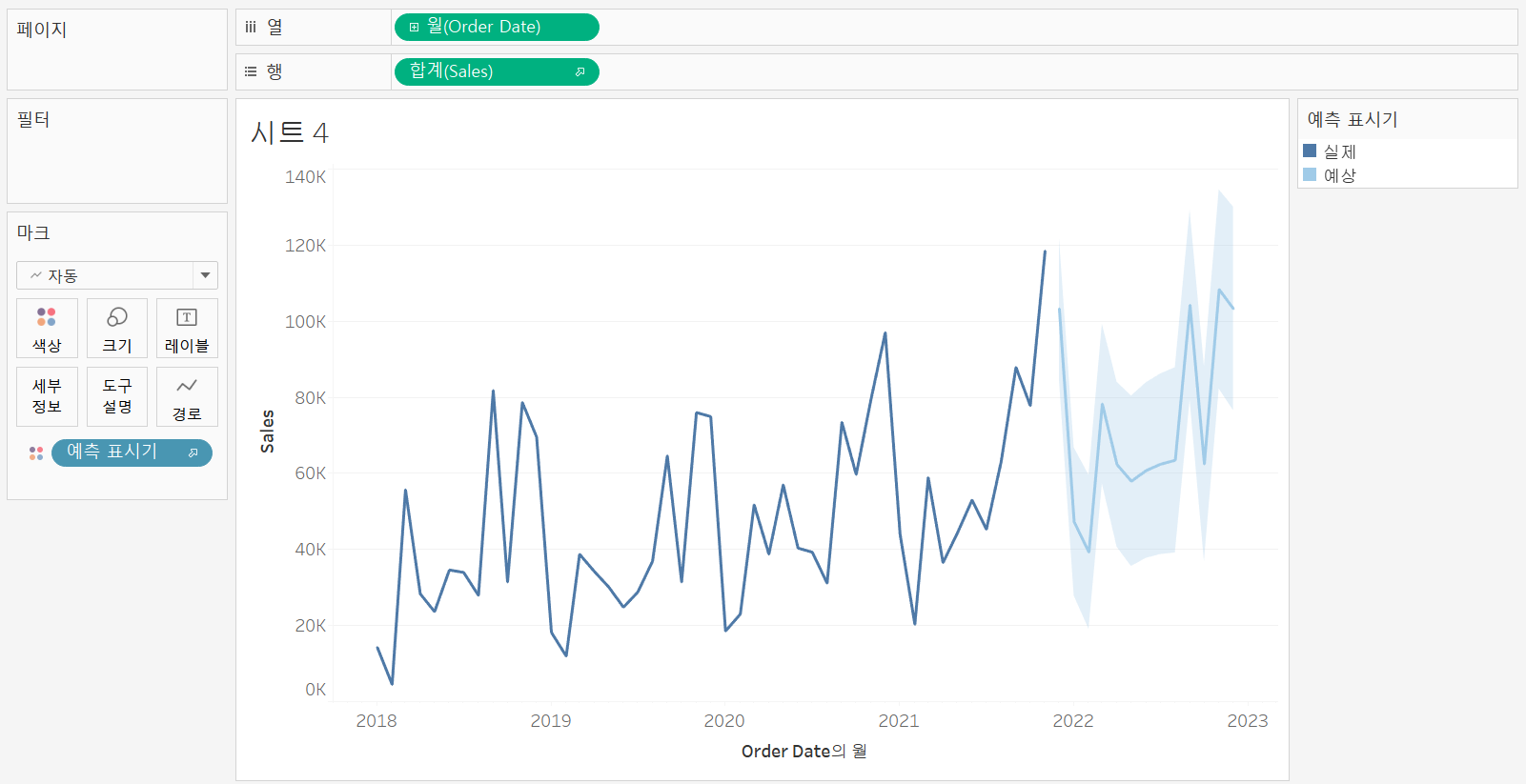
미래의 order date의 sales를 파악하기 위해 열선반에 order date의 연속형 월을, 행 선반에 sales를 올리고 분석 탭에서 예측을 시트 안에 넣어주었다. raw data엔 나타나지 않은 미래의 sales의 예측값을 제공한다.
태블로에선 예측으로 '지수 평활법(exponential smoothing'을 사용한다.
예측 라인을 우클릭하여 예측 옵션에 들어가서 지수 평활법에서 사용하는 다양한 옵션들을 선택할 수 있다.
다음 기간 무시에서 1개월을 선택하면, 기존의 데이터에서 마지막 1개월은 원본 데이터가 아닌 예측값으로 사용되고, 0개월을 선택하면, 기존의 마지막 기간까지 원본 데이터로 사용된다.

예측 기능은 불연속형 날짜 필드에 대해서도 사용할 수 있다. 열 선반에 연속형 월을 넣어주고 분석>예측을 해줘서 불연속적 order date에 대해서도 sales를 예측할 수 있다.

클러스터링
sub category 별 discount와 profit의 분포를 확인하고자 열선반에 discount, 행선반에 profit, 세부 정보에 sub category를 올렸다.

분석>클러스터로 분포를 가까운 점들을 기준으로 그루핑 할 수 있다. K-means clustering의 알고리즘을 사용했다. 마크카드의 클러스터 우클릭>클러스터 편집에 들어가면 어떤 변수가 클러스터링에 사용되었는지 확인할 수 있고 클러스터 수도 결정할 수 있다. 여기선 데이터가 4개의 클러스터로 구분되었다.
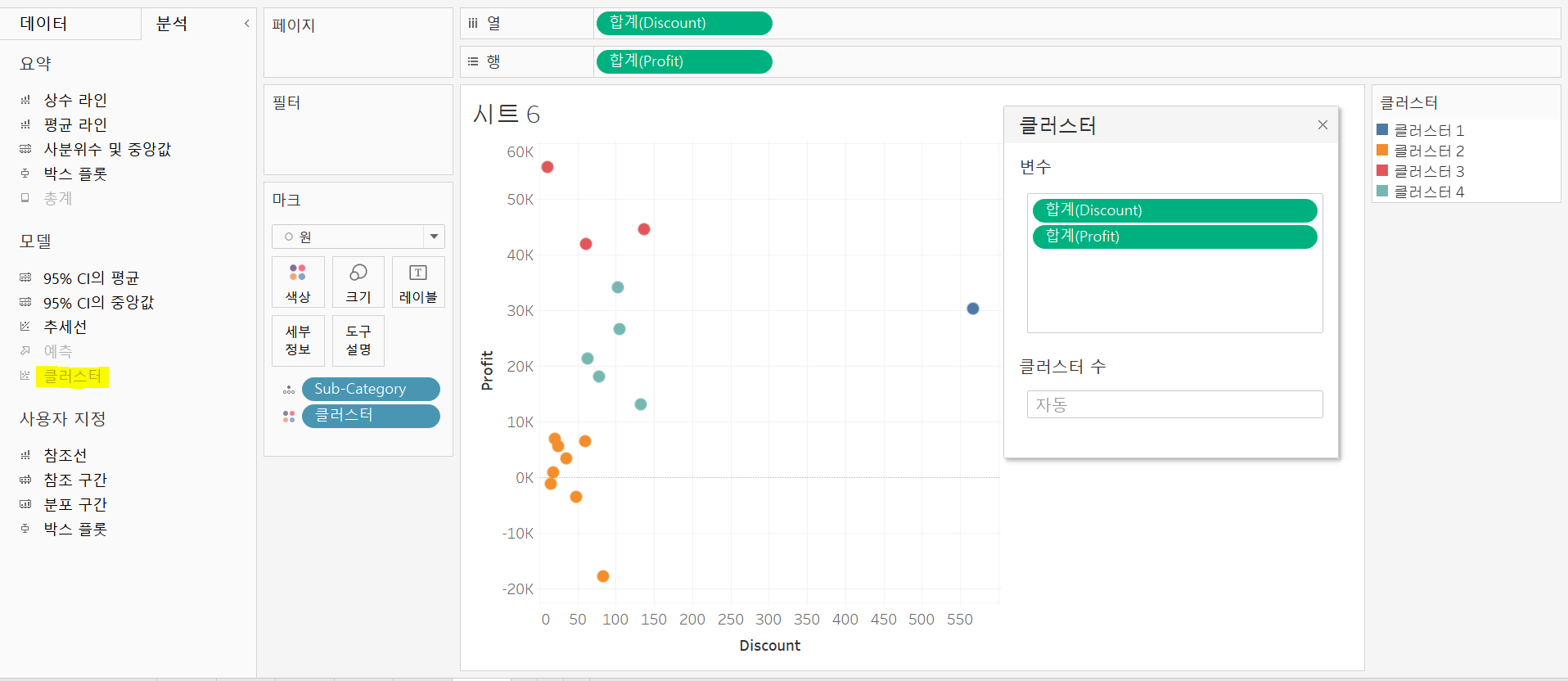
테이블에서 다른 변수들도 클러스터링에 포함시킬 수 있다. 그다지 많이 쓰이는 분석 기법은 아니다.

참조선
sub category 별 sales를 알기 위해 각각 열선반, 행선반에 올려주었다.

sub category 별 sales막대에 해당 sub category의 profit의 평균값도 표기하고자 한다. 참조선으로 활용 할 측정값이 반드시 화면 안에 들어와 있어야 하기 때문에 profit을 마크 카드의 세부정보 위로 올렸다. 전체 sub category에 대한 profit의 평균값이 아닌, 셀 별 평균값을 알고 싶기 때문에 분석 탭>참조선>'셀별'로 선택을 해주었고, 레이블도 표시할 수 있다. 레이블에는 값으로 합계(sales)가 아닌 합계(profit)을 선택한다. 참조선으로 활용하고자 하는 측정값인 profit을 시트에 올리지 않으면 여기에 profit이 나타나지 않는다.

막대의 높이는 sub category 별 sales의 합계, 참조선은 sub category 별 profit의 평균에 해당한다.

'시각화 > tableau 기초' 카테고리의 다른 글
| 태블로 주요 기능 사용하기: 계산된 필드 (0) | 2021.04.24 |
|---|---|
| 태블로 주요 기능 사용하기: 지도(Map) (0) | 2021.04.10 |
| 태블로 주요 기능 사용하기: 이중축(dual axis) (0) | 2021.04.09 |
| 태블로 주요 기능 사용하기: 필터 (추출 필터, 데이터 원본 필터, 차원 필터, 측정값 필터, 숨기기) (0) | 2021.04.09 |
| 태블로 기초: Level of Detail (LOD) (0) | 2021.04.06 |



