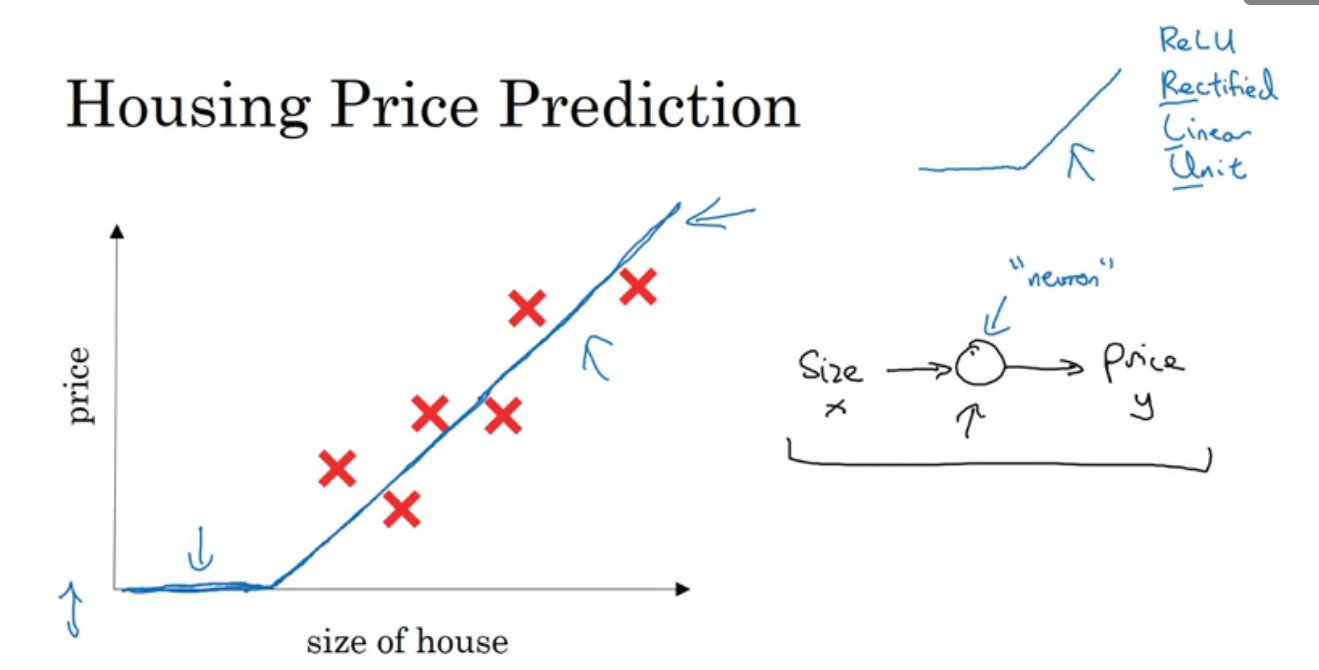
housing price를 예측하기 위한 신경망을 구현한다고 하자. 왼쪽은 집의 크기에 대한 집 가격의 그래프이고 집의 가격이 음수가 나올 수 없기 때문에 ReLU함수와 비슷한 꼴의 그래프를 그릴 수 있다. 집의 크기 외에도 다른 변수들을 고려했을 때 집값 예측을 신경망으로 어떻게 할 수 있는 지 살펴보자.
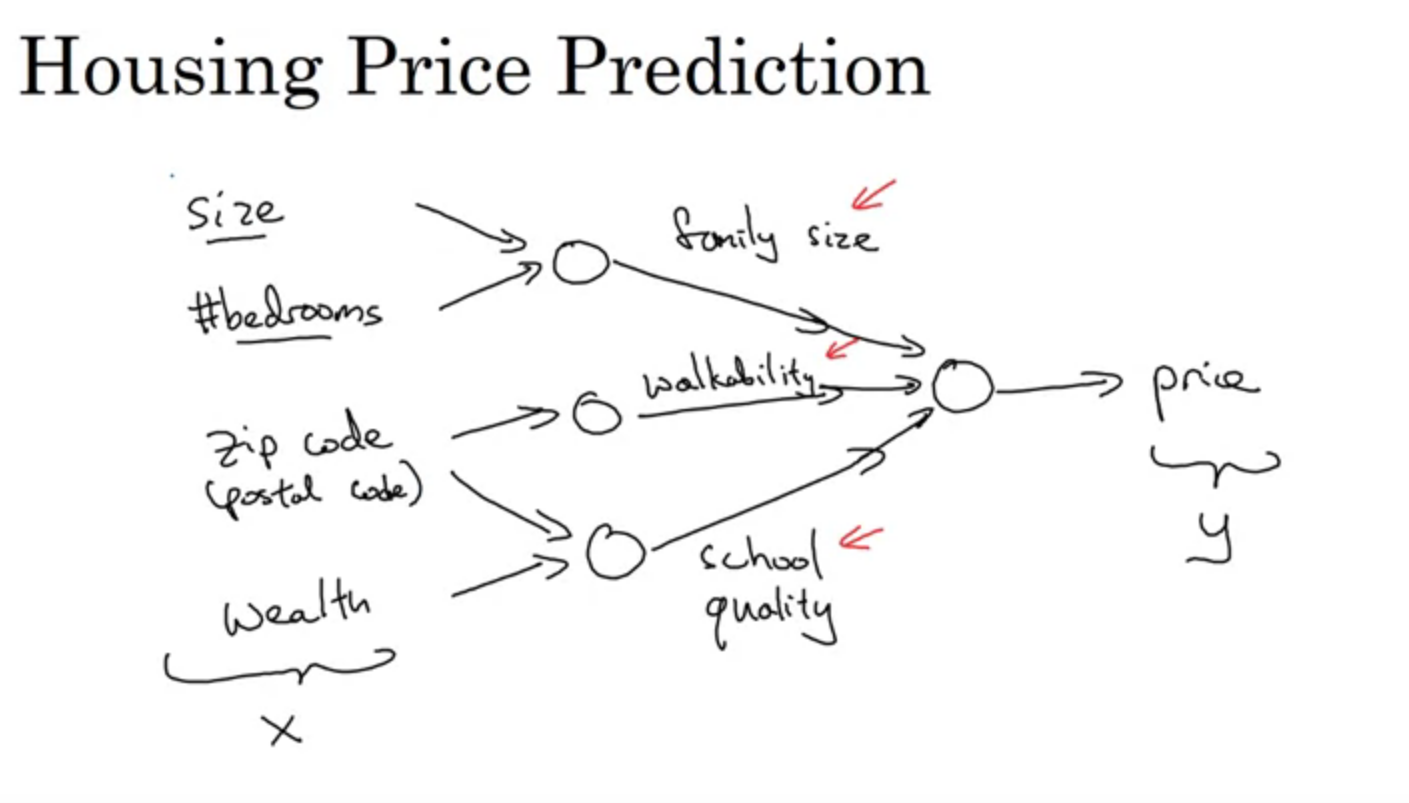
집의 크기와 방의 수는 family size라는 변수로 정의될 수 있고, 주소는 도보 이용 가능성, 주소와 재산은 교육의 질이라는 새로운 변수로 정의될 수 있다. 이러한 모든 변수들이 집의 가격이라는 예측으로 나타날 수 있다.

이처럼 신경망에서 x1, x2..의 입력층(input layer)에 따라 hidden layer의 노드들이 영향을 받고 여러 층에서 신호 전달을 거쳐 집값이라는 y의 예측값이 출력될 수 있다.
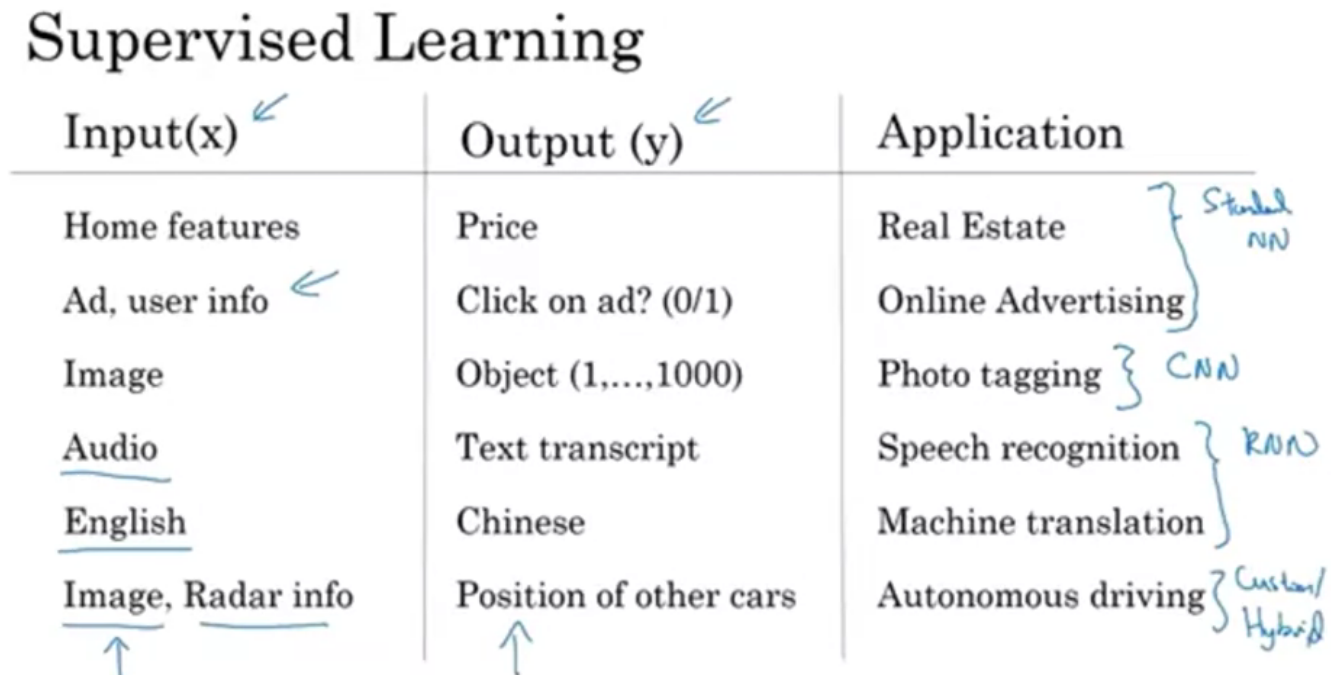
neural network를 이용한 supervised learning에는 standard NN, Convolutional NN(CNN), Recurrent NN(RNN) 등이 있다. Convolutional은 합성이란 뜻으로 neural network에서 합성곱으로 데이터를 처리한다. 시각적 영상을 분석하는데 주로 사용된다. RNN은 유닛간의 연결이 순환적이어서 Recurrent라는 단어를 쓰고 시간적인 요소를 담고 있는 sequence 데이터를 모델링하는 데 주로 사용한다. 주로 언어 관련 데이터인듯

machine learning에 이용되는 data는 structured data와 unstructured data로 나뉜다. 왼쪽 표처럼 명확하게 수치로 나타난 데이터를 structured data라고 한다. unstructured data는 음성, 사진, 텍스트 등 데이터 내부에서 작업을 통해 내용을 새롭게 인식해야 하는 데이터이고 컴퓨터가 이 데이터를 인식하고 처리하는데 시간이 더 걸린다.
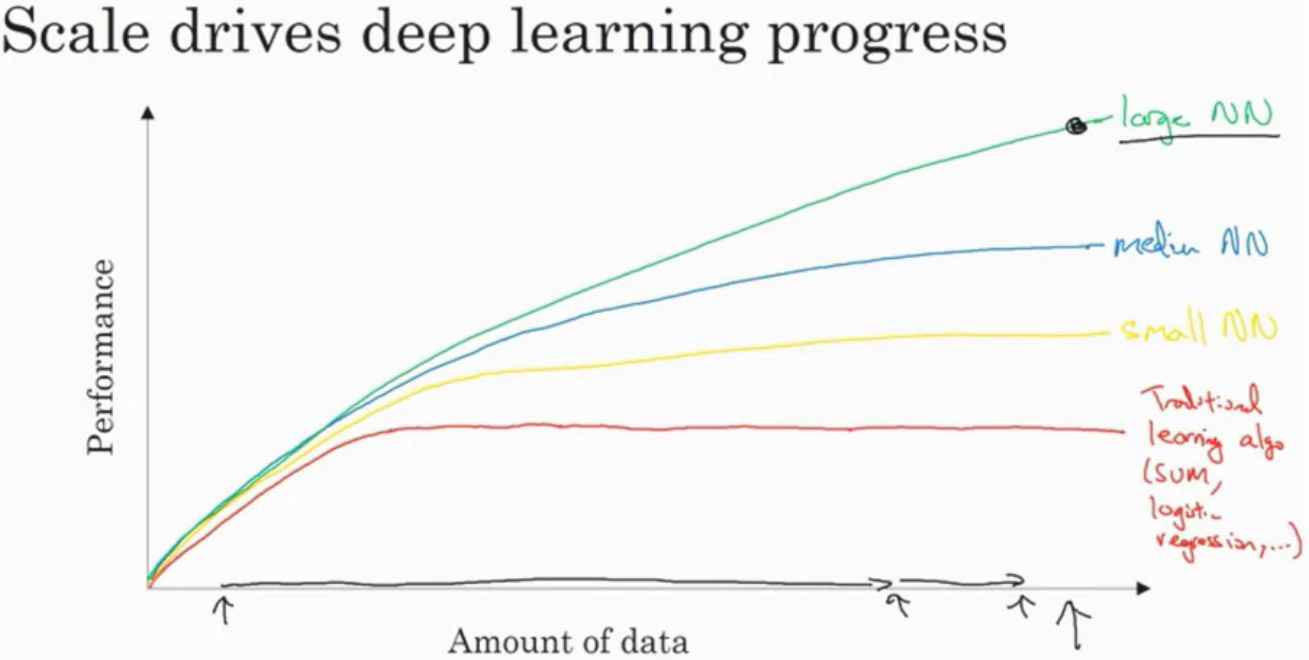
딥러닝 모델을 사용하는 이유
- 데이터가 많아질 수록 딥러닝 모델의 성능이 좋은데, 충분히 많은 데이터를 이용할 상황이 되기 때문
- 거대한 크기의 신경망을 만들 컴퓨터의 능력(CPU,GPU)이 되기 때문
'딥러닝 > DeepLearning.ai' 카테고리의 다른 글
| 3주차. Programming assignment (0) | 2021.02.05 |
|---|---|
| 3주차. Shallow Neural Network (0) | 2021.02.04 |
| 2주차. Programming: Logistic Regression with Neural Network mindset (0) | 2021.02.03 |
| 2주차. Vectorization (0) | 2021.02.03 |
| 2주차. Logistic Regression as a Neural Network (0) | 2021.02.02 |



