https://theeffectbook.net/ch-StatisticalAdjustment.html
해당 내용은 위 링크를 참고하여 작성했습니다.
Standard Error이란?
Standard Error(표준 오차): 회귀계수의 standard deviation (표준 편차)
- Standard Deviation (표준편차) vs Standard Error (표준 오차)
- Standard Deviation (S.D.): 데이터의 퍼져있는 정도를 나타낼 때 사용
- Standard Error (S.E.): 추정치의 표준편차를 나타낼 때 사용. e.g.) 표본 평균의 퍼져있는 정도를 계산할 때 → 표본 평균은 추정치이므로 Standard Deviation이 아니라 Standard Error을 사용
- 회귀분석 시 추정치에 대한 Standard Error - $SE(\hat{\beta_1})$으로 Sampling Distribution에 대한 정보를 파악할 수 있음
Standard error에 대한 가정과 가정이 틀린 경우
1) error term은 normal distribution을 따라야 함 → OLS coefficient가 normal distribution을 따른다는 가정을 만족시킴
- 많은 경우 해당 가정이 만족되지 않아도 큰 문제가 발생하지는 않음
2) iid 가정: error term이 독립적(independent)이고 동일한 분포(identically distributed)에서 나왔음
2-1) ↔ auto-correlation (자기상관)
- temporal auto-correlation (시간적 자기상관)
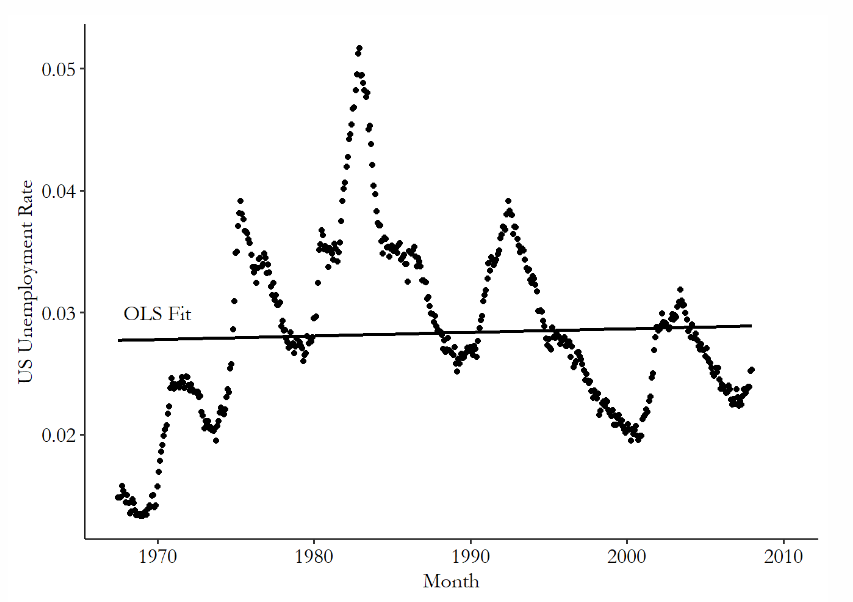
- e.g. 연도별 미국의 실업률 - temporal auto-correlation이 나타남 → error term이 양수와 음수가 반복됨 → 과거의 오차가 미래의 오차를 예측하므로 error term이 독립적이지 않기에 iid 가정을 만족하지 않음
- spatial auto-correlation (공간적 자기상관)
2-2) ↔ heteroskedasticity (이분산성)
- error term 분포의 variance가 model의 variance와 관련된 경우
- homo-skedasticity vs hetero-skedasticity
(1) homo-skedasticity (등분산성)
- $E(\epsilon_i^2) = \sigma^2$
- 어떤 i를 선택해도 error term이 같은 분포를 이룸


(2) hetero-skedasticity (이분산성)
- $E(\epsilon_i^2) = \sigma_i^2$
- i마다 error term이 서로 다른 분포를 이룸


- 예시
- e.g. 인스타그램을 하는 시간 ~ 인스타그램 팔로워의 수
- 인스타그램을 하는 시간이 적은 유저 → 인스타그램 팔로워의 수가 적고 이 때 variance가 작음 → error term의 variance가 작음
- 인스타그램을 하는 시간이 많은유저 → 인스타그램 팔로워의 수의 variance가 큼 → error term의 variance가 큼

iid 가정의 실패 → standard error의 추정치에 대한 아래의 가정이 틀리게 됨
'계량경제학 > 인과추론의 데이터과학' 카테고리의 다른 글
| Gauss-Markov Assumptions (0) | 2022.09.30 |
|---|---|
| 인과추론을 위한 회귀분석 - Standard Error을 어떻게 고치면 되는가? (1) | 2022.09.25 |
| 인과추론을 위한 회귀분석 - 상호작용항 (0) | 2022.09.21 |
| 인과추론을 위한 회귀분석 - 변수 변환 (1) | 2022.09.21 |
| 인과추론을 위한 회귀분석 - Polynomials (1) | 2022.09.21 |



