https://theeffectbook.net/ch-StatisticalAdjustment.html?panelset=python-code
Chapter 13 - Regression | The Effect
Chapter 13 - Regression | The Effect is a textbook that covers the basics and concepts of research design, especially as applied to causal inference from observational data.
theeffectbook.net
해당 내용은 위 사이트를 참고하여 작성했습니다.
(1) The basic of regression
1. Error terms

- Residual: sample과 회귀선을 통해 예측한 OLS과의 차이
- Error($\epsilon$): sample과 실제 model과의 차이
2. Regression Assumptions and Sampling Variation

- exogeneity assumption: X → Y로의 인과관계가 설명되기 위해서는 X가 $\epsilon$과 상관관계가 없어야 함.
- 실제 diagram은 아래와 같은데, OLS는 $y = \beta_0 + \beta_1X + \beta_2Z + \epsilon$으로, 변수 A는 X와 상관관계가 있으면서 $\epsilon$에 포함되어있어 backdoor path를 일으킴. 이를 위해 변수 A를 control 하는 과정이 필요함.
3. Hypothesis Testing in OLS
- Type 1 error(False Positive): H0이 참이지만 H0을 기각하는 오류
- $\alpha$ = 0.05일 때 Type 1 error rate도 0.05
- Type 2 error (False Negative): H0이 거짓이지만 H0을 채택하는 오류
- Statistical Significance
- 통계적으로 유의하지 않다는 말은 추정치가 잘못됐다는 말은 아님
- 통계적으로 유의하지 않다는 결론을 내기 두려워 하면 안됨
- b1 = 0인지의 여부 (즉, 해당 변수가 y와 상관관계가 있는지 여부)만 파악하고 끝내면 안됨
- 통계적 유의성이 ‘해당 변수가 유의함’과 큰 상관이 없을 수도 있음 (ex. 치료 방법이 IQ를 0.000001 높이는 데 통계적으로 유의한지 여부는 크게 중요하지 않음)
- Hypothesis test에서 p-value로 statistical significance를 보는 것 외에도 추정치의 정밀도(standard error)도 같이 봐야 함
4. Regression Tables and Model-Fit Statistics
- Regression Table에서 $\beta_1$의 해석
- X1을 제외하고 나머지 변수는 모두 동일한 값을 가진다고 할 때, 하나의 X1이 1만큼 높은 경우, 이 때 y는 평균적으로 $\beta_1$ 단위만큼 높다. (O)
- X1이 1만큼 증가하면 y가 $\beta_1$만큼 높아진다 (X) → OLS 추정 결과가 인과관계 자체라고 생각하면 안됨
- $\beta_1$에 해당하는 변수 X1 외의 나머지 변수를 control 하는 아이디어이고, 이는 backdoor를 차단하는 것임.
5. Subscripts in Regression Equations
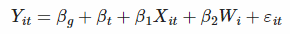
- g: i에 대한 group
- t: 시간
- i: 개인
- W: control variable, 개인에 따라 변할 뿐 시간이 지남에 따라 변하지 않는 것 (출생지 등
'계량경제학 > 인과추론의 데이터과학' 카테고리의 다른 글
| 인과추론을 위한 회귀분석 - Polynomials (1) | 2022.09.21 |
|---|---|
| 인과추론을 위한 회귀분석 - Discrete Variable (2) | 2022.09.21 |
| Causal Diagram (1) | 2022.07.30 |
| Instrumental Variable, Control Variable, Selection Model (0) | 2022.07.30 |
| Session 2: Overview of Research Design for Casual Inference (0) | 2022.03.28 |


