<기존 모델과 attention 모델의 수식 비교>
| encoder | decoder | ||
| seq2seq |  |
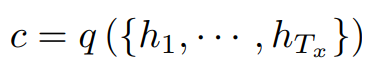 |
  |
| attention |   |
   |
 |
<Attention model Mechanism>
(1) encoder


encoder에서는 biRNN 과정을 거친다. 순방향 RNN에서는 input sequence를 앞에서부터 순서대로 읽어서 forward hidden state를 구하고, 역방향 RNN에서는 input sequence를 뒤에서부터 읽어서 backward hidden state를 계산하고 동일한 시점에 대해 forward hidden state와 backward hidden state를 concatenate 한다.
j 시점에서 encoder의 hidden state인 hj는 j시점 앞, 뒤의 단어들을 모두 포함하게 된다.
RNN은 최근의 단어들에 대해 더 초점을 맞추는 경향이 있기 때문에 hj는 xj 근처의 단어들을 더 많이 반영하고 있다.
(2) attention

attention 과정에선 c,α,e를 구해야 한다.
eij는 attention score 값으로, 이전 시점에 decoder에서 hidden state와 encoder의 hidden state가 얼마나 유사한지 나타내는 벡터이다. decoder에서 j번째 벡터에 대해 encoder의 i=1부터 Tx까지의 벡터를 모두 내적했을 때, 내적 결과가 가장 큰 벡터가 가장 유사도가 높을 것이다. 예를 들어 '나는 고양이로소이다'를 입력하여 'I am a cat'을 출력하는 기계 번역에서 'cat' 벡터를 '나','는','고양이','로소','이다' 벡터와 모두 내적한다고 하고, '고양이'와 내적시 가장 값이 크다면 '고양이'가 'cat'과 유사도가 가장 높다고 생각하는 것이다.
αij는 eij를 softmax 처리 한 것으로 0에서 1사이의 값을 가지고 동일한 i에 대해 합하면 1이 돼서 '확률적'이라고 할 수 있다. 또 α는 context vector 계산시 hj에 대한 '가중치'로 계산되므로, α를 확률적인 가중치라고 할 수 있다. α는 alignment model이라고 하여 단어간의 대응 관계를 나타낼 수 있다는 뜻이다.
ci는 context vector로, encoder의 hidden state와 attention의 가중치 값들을 곱하고 동일한 i에 대해 모두 더한 값이다.
ci는 encoder가 input sentence를 매핑하는 annotation(h1, ... , hTx)의 순서에 따라 달라진다.
hj는 입력 시퀀스의 i번째 단어를 둘러싼 부분에 강한 초점을 두고 전체 입력 시퀀스에 대한 정보를 포함한다. 가중합을 계산하여 하나의 벡터로 계산되고 이 벡터는 매 decoding 시점마다 다르므로 기존의 fixed length vector 문제를 해결할 수 있다.
(3) decoder
si는 가변 context vector를 고려한 hidden state이다. decoder에서 매 시점마다 달라지는 context vector를 반영할 수 있다. 이전 모든 시점에 대한 hidden state가 압축되어 있는 si-1, 이전의 decoder 출력값, 현재 시점의 context vector를 입력으로 하여 구한다.
* Experiment

RNNsearch-50, RNNenc-50은 train set에서 50개 이내의 단어를 input 문장으로 사용했고, 나머지는 30개 이내의 단어를 input 문장으로 사용했다.
RNNsearch는 Attention 모델, RNNenc는 RNN 모델을 사용한 것인데 Attention 모델에서 많은 단어를 input으로 사용할 수록 문장의 길이가 길어져도 일정 수준의 학습력을 유지하는 것을 확인할 수 있다.
'딥러닝 > nlp 논문' 카테고리의 다른 글
| KNU 한국어 감성사전: 논문 리뷰 (0) | 2021.07.25 |
|---|---|
| Transformer: multihead attention을 중심으로 (0) | 2021.07.25 |
| Attention 모델이란? (0) | 2021.04.04 |
| Seq2Seq (Sequence-to-Sequence) 이란? (0) | 2021.04.04 |
| LSTM (Long-Short Term Memory)이란? (0) | 2021.03.28 |


