https://www.youtube.com/watch?v=Yk1tV_cXMMU
위 동영상을 참고하여 작성했습니다.
Transformer의 구조

(1) Input Embedding
(2) Positional Encoding
(3) Encoder > Self multihead Attention
(4) Add & Normalization
(5) Feed Forward Neural Network
(6) Decoder > Masked multihead Attention
(7) (Encoder & Decoder) Multihead Attention
(8) Linear & Softmax Layer
Encoder과 Decoder

transformer에서 encoder와 decoder은 같은 개수로 여러 층이 쌓여 있는 구조이다.
각각의 encoder는 구조는 동일하지만 학습되는 가중치가 다르다. decoder 또한 마찬가지이다.

Transformer의 attention은 총 3가지 종류가 있다.
- Encoder의 Self - Attention
- Decoder의 Masked Self - Attention
- Encoder - Decoder Self - Attention
| Encoder | Decoder | |
| self attention > Feed Forward NN | 구조 | masked self attention > Encoder - Decoder Self Attention > Feed Forward NN |
| 모든 token이 masked 되어있지 않은 채로 input으로 들어오는 모든 단어를 학습 |
masked 여부 | 첫번째 층에서 자기 자신 이후의 토큰들은 모두 masked 처리하여 자기 자신과 그전 token들만을 학습 |
| 한 번에 모든 시퀀스를 사용하여 학습 | 순차성 | 순차적으로 학습 |
(1) Input Embedding

- Transformer 구조 안의 여러 Encoder 중, 맨 첫번째 encoder, 즉 input 단어를 그대로 받아들이는 encoder층에서만 input embedding이 이루어진다.
- 그 이후의 encoder들은 input embedding 없이 이전 encoder의 output을 input으로 그대로 받는다.
- input embedding의 size를 512로 정했다면, 모든 input 단어들을 512 크기의 vector로 embedding 한다.
(2) Positional Encoding

- Encoder에서는 모든 입력 sequence를 한 번에 받아들인다. 따라서 sequence의 단어들의 위치 정보는 기억되지 않는다.
- 입력 단어의 순서를 반영한 정보를 positional encoding 형태로 하여 input embedding에 더해줘서 embedding을 time series 형태로 만든다.
- 각각의 단어들 사이의 거리의 가깝고 먼 정도를 sin, cos을 이용하여 표현한다.


(3) Multihead Attention
- Self Attention 수행 이후 Feed Forward NN layer 층을 거친다.
- Self Attention layer에서 token들의 input과 output들은 서로 dependent 하다
- Feed Forward NN의 layer들은 서로 independent 하다.

(3) Self Attention

5번째 encoder의 self attention의 흐름을 나타내는 그림이다.
"The animal didn't cross the street because it was too tired" 라는 문장에서 it이 지칭하는 단어가 무엇인지, 즉 단어들 사이의 관계를 알기 위해 sequence 내의 단어들을 살펴보는 과정이다.
- Query: current word의 representation으로, 다른 단어들의 score을 매긴다.
- Key: label의 역할을 한다. Query의 한 단어와 관련된 다른 단어들을 Key를 통해 찾는다.
- Value: 실제 단어의 representation 값
① Q, K, V 계산
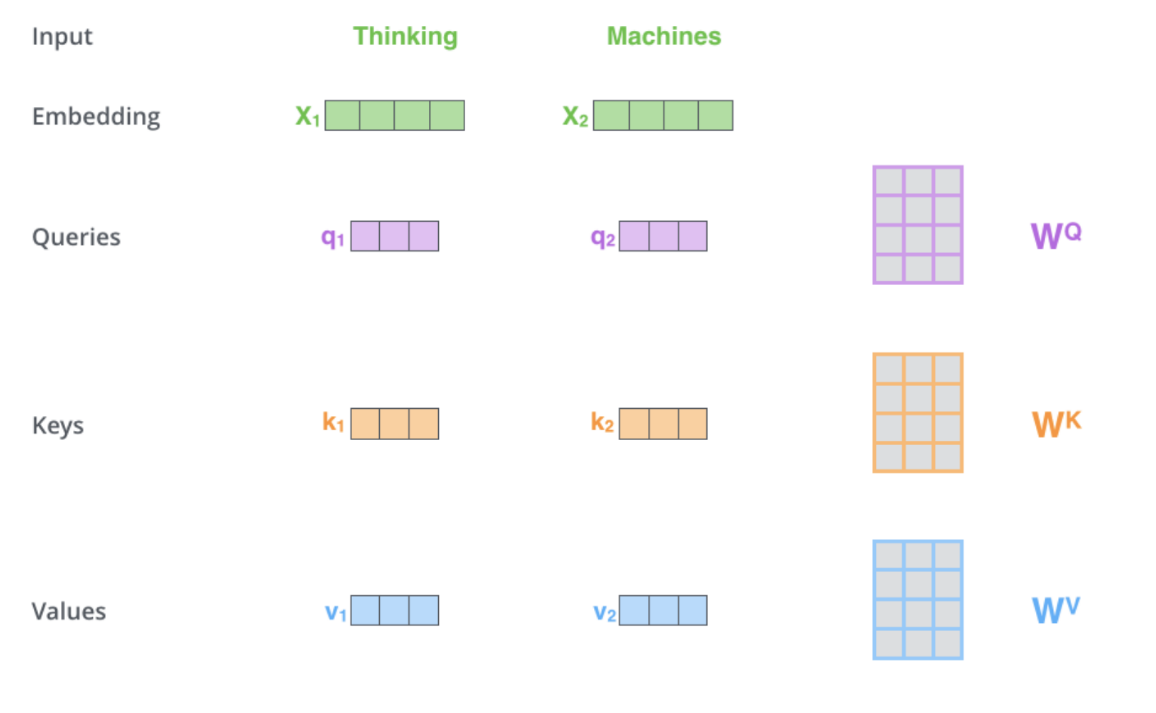
- input embedding을 Wq,Wk,Wv와 연산하여 각 단어에 대한 Q, K, V를 얻는다.
- Q, K, V의 shape이 64dim이라면, input embedding의 shape은 Q, K, V의 shape * multi head의 수로 설정해야 한다. 여기선 multi head의 개수를 8로 하여 input embedding은 64 * 8 = 512 dim을 가진다.
- 학습을 통해 Wq, Wk, Wv을 찾아내야 한다.
② Score 계산

- 특정 단어가 다른 단어들과 관련이 있는 지를 수치화 하는 과정이다.
- (multi head의 수를 8로 했을 때) Q1와 K1, K2, ..., K8를 모두 행렬곱하고 안정화를 위해 K의 dimension에 루트 씌운 값을 나누어 정규화를 수행한다. (÷√dk)
- 이렇게 얻은 값들을 softmax를 통해 v1, v2, ..., v8를 얻어 특정 토큰이 다른 토큰에 얼마나 중요한 영향을 미치는 지 계산한다.
- z1 = v1 + v2 + ... + v8으로 모든 단어에 대한 v를 계산한다.

이를 행렬로 한번에 나타낼 수 있다.
③ Concatenation

- 하나의 encoder 안에서 attention head들에서 나온 z값들을 concatenation 하여 W0 가중치와 곱해서 하나의 Z matrix를 만든다.
- ( Z0, ..., Z7 ) * W0 -> Z
(4) Residaul Addition & Layer Normalization

- Resnet에서 gradient vanishing 문제를 해결하기 위해 layer을 지난 output에 input 값을 추가적으로 더해줘서 미분해도 gradient를 유지하게 하는 방법이 있었다. 여기서도 self attention 층을 거친 Z값에 X를 추가하는 residual addition을 수행한 뒤 normalization 해준다.
- 이 과정은 encoder과 decoder의 attention, FFNN을 거칠 때마다 일어난다.
(5) Position-wise Feed Forward Neural Network


Fully Connected Layer으로, 각 position에서 동일한 가중치로 독립적으로 일어난다.
(6) Decoder > Masked Multihead Attention

- decoder의 self attention layer에서 자기 자신보다 이전 위치의 token들의 attention score만 볼 수 있도록 하는 과정이다.
- 뒷단의 score을 모두 -inf로 하면 softmax는 0이 되어 자기 자신 이전의 단어들로만 학습되도록 한다.
(7) Encoder - Decoder Multihead Attention

decoder의 Q를 encoder의 K, V로 attention을 수행하는 과정이다
(8) Linear & Softmax Layer

decoder의 output을 FC layer을 통과시킨 후 softmax를 처리하여 특정 단어에 대해 가장 확률값이 높은 단어가 최종 출력된다.
'딥러닝 > nlp 논문' 카테고리의 다른 글
| BERT(Bidirectional Encoder Representation from Transformer) (0) | 2021.10.24 |
|---|---|
| KNU 한국어 감성사전: 논문 리뷰 (0) | 2021.07.25 |
| Attention 논문 정리: Neural Machine Translation by Jointly Learning to Align and Translate (0) | 2021.04.05 |
| Attention 모델이란? (0) | 2021.04.04 |
| Seq2Seq (Sequence-to-Sequence) 이란? (0) | 2021.04.04 |


