tkdguq05.github.io/2020/08/14/Fasttext/
SISG를 활용한 Fasttext에 대해서 알아보자
자연어 처리 모델에 자주 사용되는 FastText를 뽀개보고 skipgram 모델과의 차이를 알아보자.
tkdguq05.github.io
위 페이지를 참조하여 작성한 fasttext 논문 리뷰입니다.
이전 모델들의 한계점
- 각각의 단어에 독립적으로 서로 다른 벡터를 부여함으로써 단어의 morphology, 내재적인 의미를 무시함.
- 거대한 데이터셋과 희귀 단어에 대해 embedding 정확도가 낮아서 학습이 제대로 일어나지 않는다.
FastText
- skip gram model을 기반으로 character 단위의 n-gram의 벡터들의 표현을 합치는 방법
- 하나의 단어를 n개로 잘라서 만든 subword들의 벡터값을 합친다.
- 어미, 어근을 subword로 사용함으로써 단어에 내재된 의미 파악이 가능하다.
- train set에서 없던 OOV(out of vocabulary) 단어나 희소 단어(rare word)들에 대해서, 오탈자가 있는 단어에 대해서도 학습 가능
<배경 지식>
skip gram model

- wt: target word
- wc: context word
- skip gram model에서는 target word에 대해 context word는 조건부 독립을 가정하기 때문에 target word에 대해 context word가 등장할 확률을 왼쪽과 같이 계산했고, 계산량을 줄이기 위해 log를 적용하여 오른쪽과 같이 시그마 형태로 바꿀 수 있다.
- skip gram model에서는 오른쪽의 log likelihood 함수를 최대화 해야 한다.
negative sampling

skip gram model의 training 과정에서 hidden layer에서 output layer로 넘어갈 때 W'를 거치면서 target word가 vocabulary의 모든 단어들과 행렬곱 연산을 하게 된다. 하지만 우리는 target word를 context word와 비교했을 때 score이 필요한 것이지 context word가 아닌 모든 단어들에 대해 연산할 필요가 없으므로 이 때 불필요한 연산량이 많아진다.
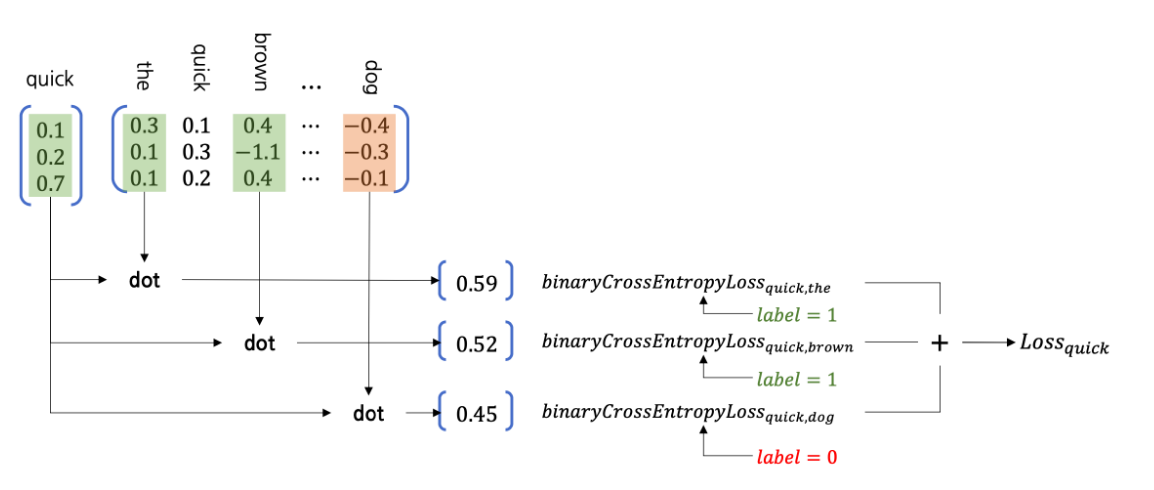
Negative sampling에서는, 모든 vocabulary 안의 단어들이 아닌 positive words, negative words에 대해서만 연산을 수행하여 계산량을 줄인다.
- positive word: target word에 대한 context word
- negative word: target word에 대한 context word가 아닌, vocabulary에서 random하기 뽑은 word
negative sampling의 추출 과정

negative word를 추출할 때는, 전체 corpus에서 사용 빈도가 가장 높은 단어들을 추출한다.
f(wi): wi라는 단어가 전체 corpus에서 등장하는 빈도 수
P(wi): wi가 전체 corpus에서의 등장 비율
따라서 P(wi)가 높은 wi로 negative sampling을 해서 skip gram model에서 효율적으로 연산할 수 있다.
FastText에서 context word의 probability 구하기
-1) softmax

- 분자의 s(wt, wc): wt가 주어졌을 때 정답값인 wc에 대한 score
- 분모의 s(wt, j): wt가 주어졌을 때 corpus 안의 모든 단어들인 j에 대한 score
- 한계: softmax로 probability를 정의하면, target word의 context words 중 하나에 대해서만 맞춘다.
- 개선: binary logistic loss로 변형하여 independent binary classification 문제로 생각한다.
-2) negative log likelihood
softmax function의 한계점 때문에 word2vec에서는 softmax function 대신 negative log likelihood 방법을 사용한다.
Nt,c는 negative sampling으로 뽑은 negative examples의 집합이다.

왼쪽 항에서 wt와 wc를 내적하는데, wt에 대해 wc의 similiarity를 높이고, 오른쪽 항에서는 wt와 negative samples를 내적하는데, wt에 대한 n의 similarity를 낮춘다.


l 함수를 정의하고 모든 target function에 대한 probability를 나타내기 위한 식을 위와 같이 작성할 수 있다.

wt와 wc의 score은 u_wt, v_wc 벡터로 나타낼 수 있고 이는 input vector, output vector로 불린다.
subword model
- "where"이라는 단어를 character 3-gram으로 나타내기
- "<wh", "whe", "her", "ere", "re>", "<where>"
- character의 접두사와 접미사에 함축된 의미를 살리기 위해 단어 앞뒤로 <,>를 붙여주고 3개의 character씩 자르고, 전체 단어까지 포함한다.
- 하나의 단어에 대해 n의 최솟값과 최댓값을 지정하여 나타낼 수도 있다.

- gw: 단어 w에서 나올 수 있는 모든 n-gram의 세트
- g: n-gram의 딕셔너리 사이즈
- zg: n-gram의 모든 벡터
'딥러닝 > nlp 논문' 카테고리의 다른 글
| Attention 모델이란? (0) | 2021.04.04 |
|---|---|
| Seq2Seq (Sequence-to-Sequence) 이란? (0) | 2021.04.04 |
| LSTM (Long-Short Term Memory)이란? (0) | 2021.03.28 |
| Word2vec 논문 리뷰 (0) | 2021.03.18 |
| NNLM, RNNLM, Word2vec (0) | 2021.03.17 |


