위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
딥러닝을 이용한 자연어 처리 입문 페이지를 많이 참고했습니다.
1. Language model
- 단어 시퀀스(문장)에 확률을 할당하는 모델
- 이전 단어들이 주어졌을 때 다음 단어를 예측하도록 함.
- 통계를 이용한 방법과 인공 신경망을 이용한 방법이 있음.
(1) 통계적 언어 모델(SLM, statistical language model)

문장 학습 이후에 이전 단어 이후에 특정 단어가 나타날 확률을 조건부 확률로 계산함.
-> 희소 문제(sparsity problem) 발생
- 모든 단어들을 독립적으로 계산하면 유사한 단어들에 대한 정보를 놓치게 되고, 이를 모두 계산하기 위해선 방대한 양의 데이터가 필요함.
- 대부분의 통계적 언어 모델에서 발생하는 문제점으로, 인공신경망 모델로 넘어가는 바탕이 됨.
N-gram model
- 통계적 언어 모델(SLM)의 일종
- 문장 안의 모든 단어를 보지 않고, 문자열을 N개의 길이를 기준 단위로 절단하여, 예측하려는 단어 앞의 일부 단어들만을 가지고 예측하는 방법
- n-gram에서 n에 들어갈 숫자들로 model의 이름이 바뀐다.
- unigram (n=1)
- bigram (n=2)
- trigram (n=3) and so on...

n=4인 n-gram에서 마지막 단어를 예측한다고 생각해보자. 마지막 단어 앞의 n-1 = 3개의 단어들로 조건부 확률을 이용하여 예측한다.

- 한계
- 자동 음성인식에 적용하기 힘들다.
- SLM이기 때문에 희소 문제가 발생하고 대량의 데이터 셋을 필요로 한다.
- n을 크게 잡으면 문장 내 근접한 단어에 대해 학습하여 정확도가 높아지지만 희소문제 발생한다는 trade-off이 존재함.
(2) 인공 신경망에서의 언어 모델
- 뒤이어 설명할 NNLM, RNNLM 등이 있음
- 단어들의 유사성을 계산하고 희소 문제를 해결하여 SLM의 단점을 보완함.
- word embedding 방법의 등장
- 단어 간 유사도를 반영한 벡터를 만드는 방법
- 이전의 one hot encoding은 0과 1의 요소만을 가진 반면, word embedding은 유사한 단어들의 요소를 비슷한 실수값으로 매칭시킨다.
- word embedding을 거치는 neural network에서 학습을 진행하면서 변화하는 가중치를 embedding vector라고 한다.
2. 다양한 language model
(1) NNLM (feed-forward Neural Network Language Model)
- 인공신경망을 사용한 NLP, word embedding 방법이 처음으로 사용된 모델
- input layer, projection layer과 hidden layer, output layer로 구성
- projection layer: hidden layer이 활성화함수로 비선형성을 띄는 반면, projection layer은 가중치와 행렬의 연산만 이루어질 뿐, 활성화 함수가 존재하지 않아 linearity가 그대로 유지되는 층.
모델링 학습 과정
- "what will the fat cat sit on" 문장 -> "what will the fat cat ____ on" 의 빈칸을 예측하는 문제
- "will", "the", "fat", "cat"의 네가지 단어로 다음 단어를 예측하고자 함.
- window: 특정 단어를 예측하기 위해 앞(또는 뒤)의 단어 몇 개를 참고할 것인지의 지표. 여기서 window size = 4

① (input layer) input 단어들을 one-hot-encoding
② (input layer -> projection layer) input의 one hot vector와 projection의 가중치가 곱해져서 W의 특정 행을 그대로 읽어온 lookup table이 만들어진다.
- input layer [N * V] -> W [V * M] -> projection layer [N * M]
- N: 입력받은 input의 수
- V: 단어 집합의 크기
- M: projection vector의 크기
- input이 projection layer를 거치면서 차원 수가 줄어든다.
- 이렇게 만들어진 e_fat은 학습을 계속하는 동안 바뀌는 embedding vector라고 한다.
- projction layer는 activation function이 없어서 이 값이 hidden layer로 그대로 들어간다.

③ (projection layer -> hidden layer) projection에서 받은 값을 W,b를 이용해 행렬곱을 하고 activation function을 거친다.

④ (hidden layer -> output layer) 행렬곱, softmax function을 수행하고 이렇게 얻은 y_hat을 실제 y값과 cross entropy로 비교하여 loss를 계산하고 back propagation으로 가중치들을 학습한다.
c.f.) 계산 복잡도 (computational complexity)
| O = E * T * Q E: training ecpoch의 수 |
- 앞으로 소개할 모델들의 성능을 계산 복잡도로 계산할 수 있다.
- 계산 복잡도가 낮으면서 정확도가 높은 모델을 좋은 모델이라고 할 수 있다.
NNLM의 계산 복잡도

| Q = N * P + N * P * H + H * V |
- N * P: (input layer -> projection layer) 단어들을 projection
- H * V : (hidden layer -> output layer)모든 단어에 대한 확률 분포를 계산, 이를 줄이기 위해 hierarchical softmax를 사용하여 H * log2(V)로 만들거나 normalized model의 사용을 피한다.
- hierarchical softmax: output layer에서 softmax 계산시 계산 비용을 줄이는 방법으로 binary classification을 통해 log2()를 씌워준다.
- N * P * H: (input layer -> projection layer)
- Huffman binary tree: 빈번하게 등장하는 단어들에 짧은 이진 코드를 부여하여 bit 수를 줄이는 방법
한계점
- n개의 단어만을 예측에 참고하여 버려지는 단어들이 생김
- 항상 같은 길이의 입력만을 받아야 함
- computational complexity가 크다.
- 중심 단어 이전의 단어들로만 예측한다.
(2) RNNLM (Recurrent Neural Net Language Model)
- NNLM 모델에서의 개선점: 입력의 길이를 고정하지 않아도 됨
- 시점(time step) 개념 도입하여 RNN(Recurrent Neural Network)을 언어 모델에 적용함.

모델링 학습 과정
- "what will the fat cat sit on"이라는 문장
- 이전 시점의 출력이 현재 시점의 입력으로 들어온다.
- test 할 때 "what will the fat"이 입력으로 들어오면 "sit"을 예측한다.
- teacher forcing(교사 강요): RNN 모델의 훈련 과정에서 t 시점의 출력이 t+1 시점의 입력으로 들어가는 훈련 기법
- teacher forcing 방법으로 RNN 훈련이 효율적으로 일어난다.
- input layer, embedding layer (linear), hidden layer (nonlinear), output layer로 구성된다.

① (input layer) input을 one hot encoding 한다.
② (input layer -> embedding layer) NNLM의 projection layer를 RNNLM에서는 embedding layer라고 한다.
③ (embedding layer -> hidden layer) embedding vector인 e_t를 이전 시점의 은닉 상태인 h_t-1과 함께 현재 시점의 은닉 상태인 h_t를 계산한다.
④ (hidden layer -> output layer) 행렬곱을 하고 softmax를 한 y_hat을 실제 y값과 비교하여 loss를 계산하고 back propagation으로 가중치들을 update 한다.
RNNLM의 계산 복잡도
| Q = H * H + H * V |
- time-delayed connection을 사용하여 hidden layer에 recurrent 한 연결이 있어서 이전의 정보에 대한 단기기억을 가질 수 있다.
- H * H: (hidden(t-1) -> hidden(t))
- H * V: (hidden -> output) hierarchical softmax로 H * V 대신 H * log2(V)를 사용할 수 있다.
한계점
- computational complexity가 여전히 높다.
(3) Word2Vec
- 이전의 nlp 모델들의 높은 computational complexity가 hidden layer에서 nonlinearity를 제공하는 과정에서 생긴다는 것을 알게 됨. 이를 사용하지 않는 단순한 모델을 강구하여 탄생
- distributed representation (분산 표현)
- 희소 표현을 극복하기 위한 방안으로, 단어들의 의미를 다차원 공간에 벡터화 하는 방법
- '비슷한 위치에서 등장하는 단어들이 비슷한 의미를 지닌다'는 가정에서 출발함
- 벡터의 차원이 줄어들고 단어의 유사성 계산 가능
- CBOW + SkipGram
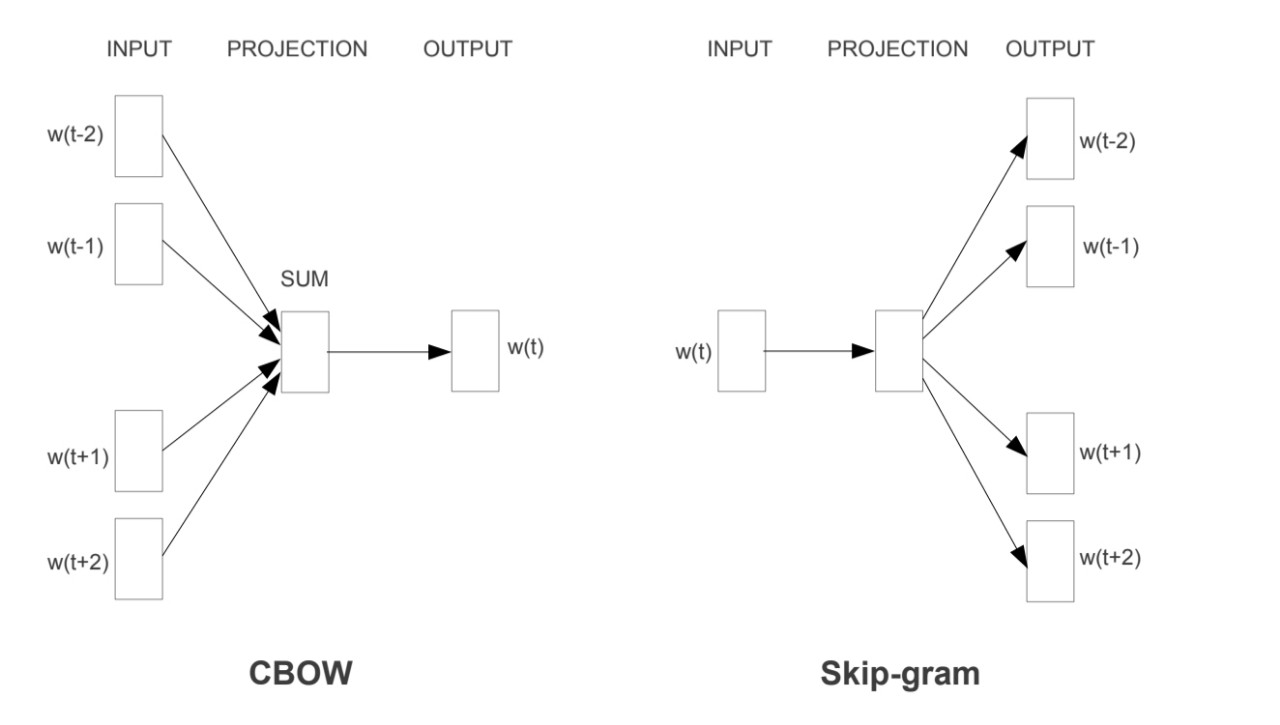
| CBOW | Skip-Gram |
| 주변 단어들로부터 중간 단어를 예측하는 방법 | 중간 단어로부터 주변 단어들을 예측하는 방법 |
-1) CBOW (Continuous Bag of Words)
모델링 학습 과정
- input layer, projection layer, output layer
- projection layer에 activation function이 없어서 linearity가 유지된다.
- "The fat cat ___ on the mat"의 빈칸에 "sat"이 들어감을 예측하기
- 주변 단어 (context word): "fat, cat, on, the" (window size=2일 때)
- 중심 단어 (center word): "sat"
- window: 중심단어 앞뒤로 몇 개의 문장으로 예측할 것인지
- sliding window: training 과정에서 중심단어와 주변단어를 바꿔가며 window 크기에 따라 training set을 바꾸는 과정


① (input layer) input에서 window size만큼 주변단어를 선택하여 one hot vector를 만든다. 하나의 중심 단어에 대해 여러 개의 주변 단어들이 input으로 들어온다.
② (input layer -> projection layer): 각 input에 대해 가중치가 곱해지고 input 개수만큼 look up table이 생성된다. n개의 input이 들어오면 생성된 n개의 look up vector를 평균 내주어야 한다. look up table을 거쳐 생성된 v_fat, v_cat, v_on, v_the를 분자로, 2 * (window size)를 분모로 넣어줘서 v 벡터를 만들어준다. 여기에 activation function은 거치지 않는다.
③ (projection layer -> output layer): 행렬곱을 하고 softmax 함수를 취하여 구한 y_hat을 실제 y값과 cross entropy로 비교하여 loss를 계산하고 back propagation으로 가중치를 update 한다.
개선점
- projection을 거치면서 word vector들을 평균 내주기 때문에 input으로 들어오는 단어들의 순서를 고려하지 않아도 된다.
- 중심단어 앞, 뒤 단어들을 모두 고려한다.
- projection layer이 모든 단어에 공유되도록 하여 모든 단어들이 동일한 위치에 project 되도록 한다.

CBOW의 계산 복잡도
| Q = N * D + D * log2(V) |
- N * D : projection
- D * log2(V): projection -> output
-2) continuous Skip-Gram model

CBOW와 반대 방향의 모델로, 중심 단어로부터 주변 단어를 예측하는 모델이다.
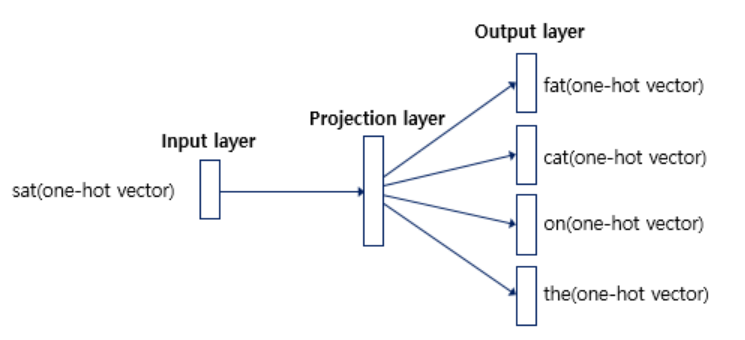
- CBOW와 다르게 벡터들의 평균을 구하는 과정이 불필요하다.
- window size를 늘려서 학습의 질을 높일 수 있지만 계산 비용이 증가한다.
- 멀리 떨어진 단어들에 대해 가중치를 적게 둘 수 있다.

Skip-Gram model의 계산 복잡도
| Q = C * (D + D * log2(V)) |
- C: 단어 사이의 최대 길이
'딥러닝 > nlp 논문' 카테고리의 다른 글
| Attention 모델이란? (0) | 2021.04.04 |
|---|---|
| Seq2Seq (Sequence-to-Sequence) 이란? (0) | 2021.04.04 |
| LSTM (Long-Short Term Memory)이란? (0) | 2021.03.28 |
| FastText (0) | 2021.03.18 |
| Word2vec 논문 리뷰 (0) | 2021.03.18 |


