1. import packages
import os
from os.path import join
import copy
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import sklearn
import matplotlib.pyplot as plt
adult_path = join( 'adult_data.csv')
column_path = join( 'adult_names.txt')
adult_columns = list()
for l in open(column_path):
adult_columns = l.split() #adult_columns에 변수명을 리스트로 저장
2. 데이터 불러오기
data = pd.read_csv(adult_path, names = adult_columns) label = data['income'] del data['income'] data.head()
label
0 <=50K
1 <=50K
2 <=50K
3 <=50K
4 <=50K
5 <=50K
6 <=50K
7 >50K
...
data.shape() #(48842, 14) data.info()
3. Preprocessing
data = pd.get_dummies(data) data.head() data.shape() # (48842, 108)
Pandas의 get_dummies 함수를 사용해 범주형 변수를 One-Hot Encoding한다.
수치형 변수는 그대로 두고 범주형 자료는 모든 값이 0또는 1로 될 수 있도록 변수 개수를 늘린다. (14열에서 108개 열으로 늘어남)
label = label.map(lambda x : 0 if x =='>50K' else 1)
label label 데이터에서 값이 '>50K'이면 0으로, 값이 '<=50K'이면 1로 값을 바꿈
4. Cross Validation
from sklearn.model_selection import train_test_split # train test split X_train, X_test, y_train,y_test=train_test_split(data,label,test_size=0.2,random_state=785) # train validation split X_train,X_valid,y_train,y_valid=train_test_split(X_train,y_train,test_size=0.2,random_state=785)
random_state: split 하기 전에 데이터를 shuffling 할 것인지. int를 할당하면 int가 random seed가 된다.
from sklearn.ensemble import RandomForestClassifier rf=RandomForestClassifier(random_state=785) rf.fit(X_train, y_train)
sklearn의 ensemble 패키지에서 RandomForestClassifer을 불러오고 train set에 모델을 학습한다.
# Valid 데이터로 검증
from sklearn.metrics import accuracy_score
y_pred = rf.predict(X_valid)
accuracy = accuracy_score(y_valid, y_pred)
print("random forest validation set accuracy : {:.2f}%".format(accuracy_score(y_valid,y_pred)*100))
# Test 데이터로 모델 평가
y_pred_test = rf.predict(X_test)
accuracy_test = accuracy_score(y_test, y_pred_test)
print("random forest test set accuracy : {:.2f}%".format(accuracy_score(y_test, y_pred_test)*100))random forest validation set accuracy: 84.29%
random forest test set accuracy: 84.70%
아직 validation set에서 검증을 통해 train set을 변형시킨 게 아니므로 validation set과 test set의 accuracy가 거의 동일하게 나온다.
5. Parameter Tuning
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100],
'max_depth' : [6, 8, 10, 12],
'min_samples_leaf' : [8, 12, 18 ],
'min_samples_split' : [8, 16, 20]
}
# RandomForestClassifier 객체 생성 후 GridSearchCV 수행
rf_clf = RandomForestClassifier(random_state = 0, n_jobs = -1)
grid_cv=GridSearchCV(rf_clf, param_grid = params, cv = 3, n_jobs = -1)
grid_cv.fit(X_train, y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))random forest의 hyperparameter
- n_estimators : 생성할 tree의 개수 (이만큼의 tree를 평균내어 성능 평가)
- max_depth : tree의 최대 깊이 (한 가지에서 몇개까지 노드가 뻗어 나갈 지)
- min_samples_leaf : node를 분할 후에 분할된 node 안에 최소한 sample data가 몇개는 있어야 하는지
- min_samples_split : node를 분할 하기 전에 최소한 데이터가 몇 개는 있어야 분할을 하는 지
최적 하이퍼 파라미터: {'max_depth': 12, 'min_samples_leaf': 8, 'min_samples_split': 8, 'n_estimators': 100}
최고 예측 정확도: 0.8565
from sklearn.model_selection import cross_val_score
# 위에서 나온 최적 하이퍼 파라미터로 모델을 학습시킴
rf_clf1 = RandomForestClassifier(n_estimators = 100,
max_depth = 12,
min_samples_leaf = 8,
min_samples_split = 8,
random_state = 0,
n_jobs = -1)
rf_clf1.fit(X_train, y_train)
pred=rf_clf1.predict(X_test)
print('예측 정확도: {0:.4f}'.format(accuracy_score(y_test , pred)))예측 정확도: 0.8629
6. feature importance
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
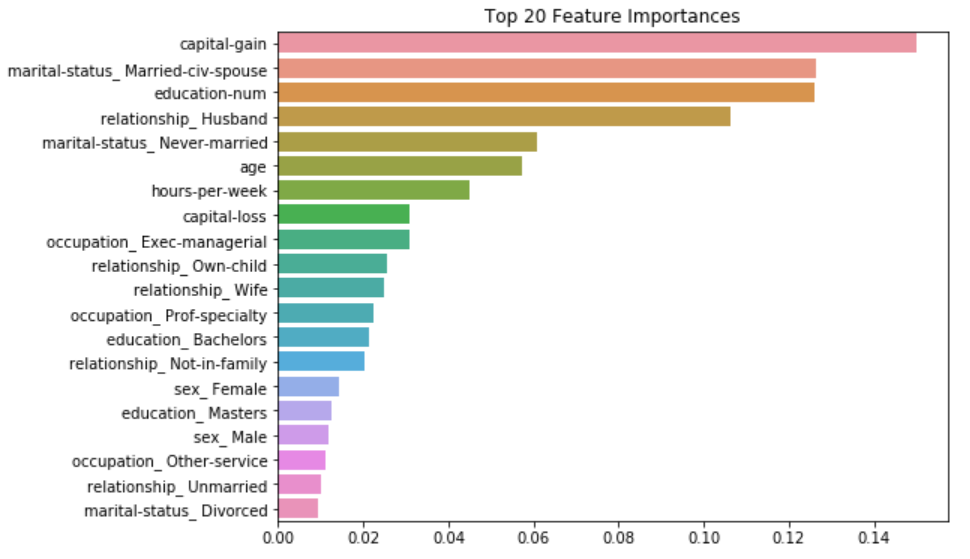
ftr_importances_values = rf_clf1.feature_importances_
ftr_importances = pd.Series(ftr_importances_values, index = X_train.columns)
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8,6))
plt.title('Top 20 Feature Importances')
sns.barplot(x=ftr_top20, y=ftr_top20.index)
plt.show().feature_importances_: 각 변수의 중요도가 저장되어 있음
ftr_importances: 각 변수명과 feature importance 수치가 매칭됨
7. Voting
from sklearn.ensemble import VotingClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, ExtraTreesClassifier
from sklearn.svm import SVC
from sklearn.model_selection import cross_validate
models=[('rfc',RandomForestClassifier()),
('ada',AdaBoostClassifier()),
('etc',ExtraTreesClassifier())]RandomForestClassifier, AdaBoostClassifer, ExtraTreesClassifier 총 세개의 모델로 voting을 해줄 것이다.
-1) soft vote
soft_vote=VotingClassifier(models, voting='soft')
soft_vote.fit(X_train,y_train)
soft_vote_pred=soft_vote.predict(X_test)
print("soft vote accuracy:",accuracy_score(soft_vote_pred,y_test))위에서 세개의 모델을 합쳐서 만든 models로 VotingClassifier에 soft voting을 위해 넣어준다.
train set을 soft vote를 위한 model에 학습시키고 이 model에 test set에 대해 predict 한다.
soft vote accuracy: 0.8497287337496161
-2) hard vote
hard_vote=VotingClassifier(models, voting='hard')
hard_vote.fit(X_train,y_train)
hard_vote_pred=hard_vote.predict(X_test)
print("hard vote accuracy ",accuracy_score(hard_vote_pred,y_test))위에서 세개의 모델을 합쳐서 만든 models로 VotingClassifier에 hard voting을 위해 넣어준다.
train set을 hard vote를 위한 model에 학습시키고 이 model에 test set에 대해 predict 한다.
hard vote accurcy: 0.8567918927218753
'머신러닝 > 분석 base' 카테고리의 다른 글
| Resnet (0) | 2021.02.23 |
|---|---|
| Boosting & Adaboost (0) | 2021.02.09 |
| Bagging & Random Forest (0) | 2021.02.09 |
| SVM: programming (0) | 2021.02.08 |
| SVM (Support Vector Machine) (0) | 2021.02.08 |


