6.1 매개변수 갱신
최적화(optimization): 손실 함수의 값을 가장 작게 하는 매개변수를 찾는 과정
(1) 확률적 경사 하강법 (SGD: Stochastic Gradient Descent)

loss function의 기울기 * 학습률을 빼가면서 W를 update 한다. 즉 Loss function이 기울어진 방향으로 일정 거리만큼 가는 방법.
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]params 매개변수들에 대해 learning rate * key에 대한 gradient만큼 빼주는 방법이다. SGD에서 update는 params가 특정 값으로 수렴할 때까지 반복된다.
SGD의 단점

SGD는 현재 장소에서 기울어진 방향을 따라서 이동하는데, 현재 위치에서 기울어진 방향이 global minimum의 방향과 차이가 날 수 있어서 지그재그를 그리면서 비효율적인 경로를 따라 움직인다. (이렇게 방향에 따라 기울기가 달라지는 함수를 비등방성 함수라고 한다.)
(2) 모멘텀 (Momentum)


v는 속도를 나타낸다. Loss function에서 기울기가 가파르면 v가 커지고 기울기가 완만하면 v가 작아진다.
SGD에서는 loss function의 기울기에 따라 W를 update 하는 비율이 learning rate로 일정했는데, 모멘텀에서는 loss function의 기울기에 따라 W를 update 하는 비율이 달라진다.
v가 크면 W가 크게 움직이고 v가 작으면 W가 조금 움직인다.
class Momentum:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
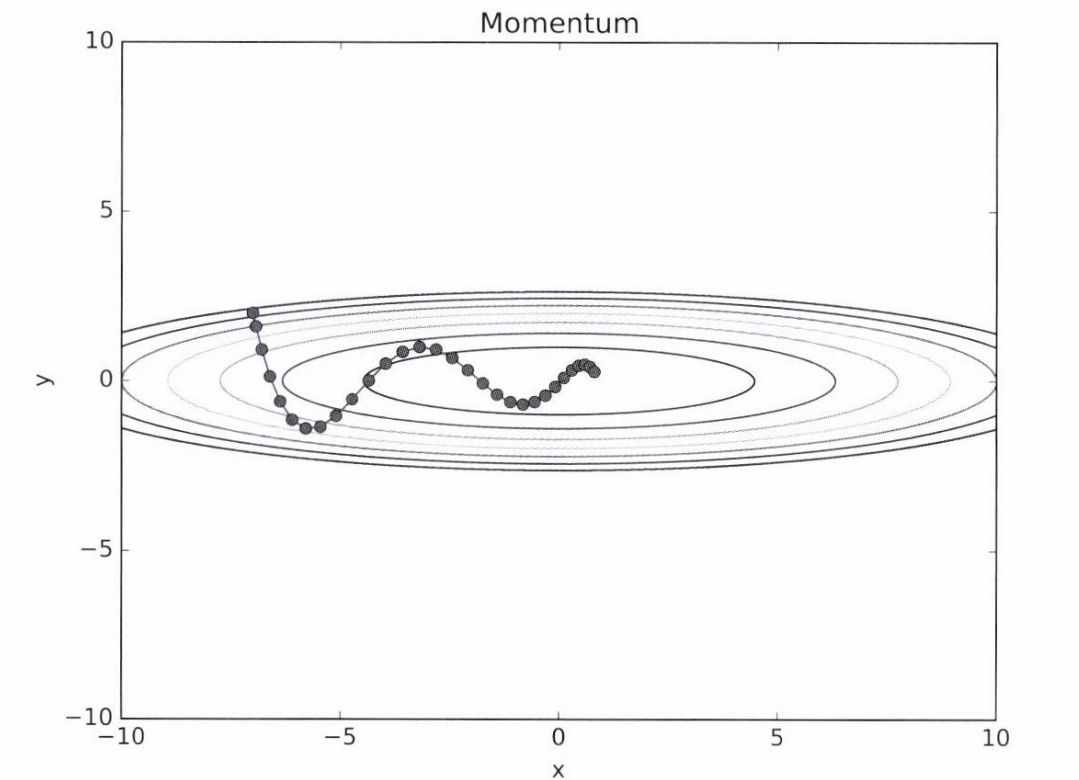
SGD에 비해 지그재그 정도가 덜하고, global minimum에 더 효율적인 경로로 도달한다. f(x,y)의 기울기가 x축은 완만하고 y축은 가파르게 변한다. x축은 일정한 방향으로 가속하고 y축의 방향 속도는 일정하지 않아서 x축으로 빠르게 다가간다.
(3) Adagrad
학습률 감소(learning rate decacy): 학습을 진행하면서 학습률을 점차 줄여나가는 방식. 매개변수 전체의 학습률을 일괄적으로 줄일 수 있고, Adagrad에서는 각각의 매개변수에 맞춤형 값을 만들어준다.

h는 grad를 원소별로 제곱하여 더해준 값이다. 매개변수 갱신시에는 SGD와 기본적으로는 동일한데, 학습률에 1/√h를 곱해준다. L의 변화율이 큰 (dL/dW^2가 큰) 원소는 (1/√h가 작아서) W가 조금 바뀌고 L의 변화율이 작은 (dL/dW^2가 작은) 원소는 (1/√h가 작아서) W가 크게 바뀐다. 즉, 매개변수의 원소마다 학습률이 다르게 적용되고, W가 많이 바뀌어서 학습이 많이 된 원소는 학습률이 줄어들게 된다.
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
# 1e-7 : h[key]에 0이 있는 경우 0으로 나누는 것을 방지. 이 값도 설정 가능
L이 최솟값을 향해 빠르고 효율적으로 움직인다. y의 변화 폭이 크기 때문에 초기에는 y 방향으로 크게 움직이지만, h값이 커져서 학습률이 작아진다.
(4) Adam
Adam은 momentum과 AdaGrad를 합친 방법이다.

momentum과 비슷하지만 공의 좌우 흔들림이 적다.
=> Optimization 방법의 선택은 데이터 의존적이기 때문에 여러 상황을 고려하여 선택해야 한다.
+) MNIST 데이터셋으로 본 optimization 방법의 비교

SGD에 비해 Adam, AdaGrad, Momentum의 학습 진도가 더 빠르다. 다만 세 종류의 학습 성능은 hyperparameter에 의해서도 달라질 수 있다.
참고> 활성화 함수에서의 문제점
sigmoid 함수의 단점
- saturation이 일어난다.
- sigmoid의 output의 중심이 0에 위치하지 않아 zigzag 현상이 발생한다.
- 계산 비용이 비싸다.
(참고: sigmoid 함수는 activation function으로써 장점이 없고 마지막 output layer로의 함수로만 사용한다.)
(1) Saturation과 기울기 소실(gradient vanishing)
gradient의 변화량이 매우 작아지면 (dL/dW가 작아지면) 신경망의 학습이 제대로 이루어 지지 않고 loss가 낮아지지 않게 된다. 대표적으로 sigmoid 함수에서 layer에 대한 input이 6,-6만 되어도 그 때의 기울기는 0이 되어 back propagation을 할 때 dL/dW가 0이 되어 W의 업데이트가 일어나지 않을 것이다.
dL/dW = 0이 되는 것을 saturation이라고 하고 saturation을 포함하여 W의 업데이트가 없어지는 모든 현상을 gradient vanishing이라고 한다.

(2) ZigZag 현상
- 함숫값의 중심이 0이 아닌 활성화 함수(sigmoid, ReLU)에서 zigzag 현상이 발생한다.
- Loss가 가장 낮은 지점을 찾아 가는데 정확한 방향으로 가지 못하고 zigzag로 수렴해서 학습이 느려진다.


6.2 가중치의 초깃값
가중치 감소(weigh decay): overfitting을 막기 위해 가중치 값을 작게 하는 방법
모든 가중치 초깃값을 0으로 설정한다면?
- 모든 층의 가중치가 고르게 설정되어 문제가 생긴다.
- 순전파의 입력층의 모든 가중치가 0이라면, 다음층에 같은 값이 전달되고 그 다음층에도 같은 값이 출력되어 전달되기 때문에 가중치를 여러개 갖는 의미를 상실한다.
가중치의 초깃값을 잘못 설정했을 때 문제점
- 기울기 소실 문제나 표현력의 한계를 가질 수 있음.
- local-minimum에 빠질 수 있음.
=> 가중치 초깃값 설정에 유의해야 함
가중치 초깃값의 표준편차에 따른 활성화 결괏값
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.random.randn(1000, 100) # 1000개의 데이터
node_num = 100 # 각 은닉층의 노드 수
hidden_layer_size = 5 # 은닉층이 5개
activations = {} # 활성화값을 저장
for i in range(hidden_layer_size):
if i != 0:
x = activations[i-1]
w = np.random.randn(node_num, node_num) * 1
a = np.dot(x, w)
z = sigmoid(a)
activations[i] = z
100개의 뉴런을 가지는 5개의 층의 network이고 1000개의 example로 propagation 한다고 하자. 가중치는 정규분포를 따르고 각 층의 활성화 함수는 sigmoid 이고 각 층의 활성화 결과를 activations 딕셔너리에 저장한다. activations[0]~activations[4]에 100 * 100의 활성화 결과가 저장된다. example의 분산에 따라 activations에 저장된 값의 분포가 어떻게 바뀌는 지 살펴보겠다.
-1) 가중치의 표준편차가 1일 때

w=np.random.randn(node_num, node_num) * 1로 설정했을 때, 각 층의 활성화 결과가 0과 1에 치우쳐있다.

가중치의 표준편차가 1일 때 sigmoid 함수를 처리하면 결과값 y가 주로 0 또는 1의 값을 가진다. 두 경우 모두 미분은 0이 돼서 역전파의 값이 소실되는 기울기 소실 문제가 발생한다.
-2) 가중치의 표준편차가 0.01일 때

w=np.random.randn(node_num, node_num) * 0.01로 설정했을 때 각 층의 활성화 결과가 0.5에 치우쳐 있다. 다수의 뉴런이 비슷한 출력값을 가지므로 표현력이 제한된다는 문제가 발생한다.
활성화 함수에 따른 가중치 초깃값 설정
(1) Xaiver 초깃값
가중치의 초깃값의 표준편차가 1/√n이 되도록 설정하는 방법 (n:앞 층의 노드 수)

node_num = 100 # 앞 층의 노드 수
w = np.random.randn(node_num, node_num) / np.sqrt(node_num)
Xaiver로 가중치를 초기화 하니 각 층의 활성화 결과가 특정 범위에 치우치지 않고 비교적 고르게 퍼져있다.
(2) He 초깃값
Xaiver 초깃값은 활성화 함수가 선형 함수일 때 사용하면 좋다. (S자 곡선을 이루는 sigmoid, tanh 함수는 중앙 부근을 선형 함수라고 볼 수 있다.) 활성화 함수가 ReLU 인 경우엔 He 초깃값으로 가중치의 초깃값을 설정한다. He는 초깃값의 표준편차가 2/√n이 되도록 한다.

He 초깃값을 사용했을 때만 층별로 활성화 결과가 균일하게 나타난다.
+) bias의 초깃값 설정
모든 b의 초깃값을 0으로 설정하는 것이 일반적이다.
MNIST 데이터셋으로 본 가중치 초깃값 비교

MNIST 데이터셋에서는 활성화 함수로 ReLU를 사용했기 때문에 Xaver에 비해 He 초깃값 설정시 결과가 좋다. 반면 std=0.01로 설정했을 때는 학습이 거의 이루어지지 않았다.
6.3 배치 정규화 (Batch Normalization)
- 학습 하는 전체 과정을 안정화하여 각 층이 활성화 값을 적당히 퍼트리도록 강제하는 방법
- 정규화: model이 local optima에 빠지는 것을 막아준다.

- internal covariance shift: 입력값이 layer을 통과할 때마다 input의 분산이 달라지는 것. 이를 막기 위해 각 층의 활성화 결과의 분산을 의도적으로 조정하는 과정이 필요하다.
- whitening: 활성화값의 분산을 조절하기 위해 모든 층을 N(0,1)로 정규화 했을 때 whitening (백색잡음)이 발생한다.
- Batch Normalization의 필요성이 제시된다.
- 미니 배치의 평균과 분산을 이용하여 정규화 한 후에 scale 및 shift를 조절하는 과정
배치 정규화의 장점
- 학습 속도를 빠르게 한다.
- 초깃값에 크게 의존하지 않는다.
- 오버피팅을 억제한다.
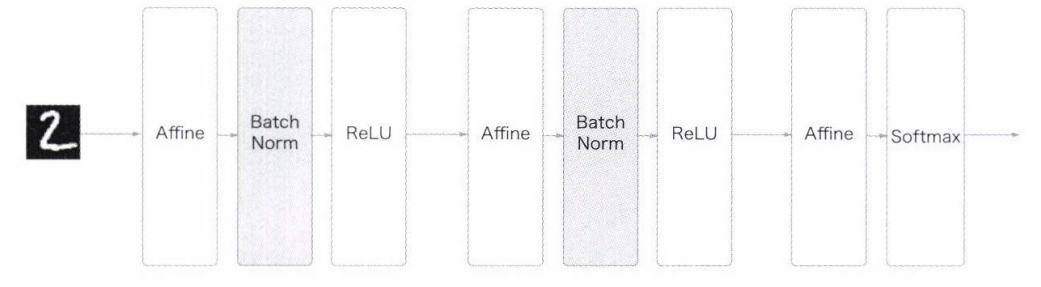
n개의 example이 있을 때 각 층에서 m개의 미니배치를 단위로 정규화 하여 학습을 하는 과정이다.

각 층에서 B = {x1, x2, ... , xm}의 m개의 example에 대해 평균과 분산을 구하고, x1 ~ xm을 정규화 하여 평균이 0, 분산이 1인 정규화 된 x1_hat ~ xm_hat을 구한다.
(입실론은 xi_hat 계산시 분모가 0이 되는 것을 막아주는 역할을 하고 아주 작은 값을 가진다.)

배치 정규화 계층마다 정규화된 데이터에 대해 확대(scale, γ)와 이동(shift, β)을 적용할 수도 있다.


Scale과 Shift의 사용 이유

활성화 함수는 데이터를 비선형으로 만들어주는 역할을 하는데, Batch Normalization으로 데이터를 계속 정규화 하게 되면 활성화 함수가 비선형의 역할을 상실하게 된다. 이전 layer의 정규화 배치를 거친 활성화 결과로 평균이 0, 분산이 1인 값을 뒤의 layer가 받게 된다. 따라서 95%의 입력값은 x = -1.96 ~ 1.96의 값에 위치하는데 이 때는 sigmoid가 선형이어서 활성화 함수를 거치면 활성화 결과가 비선형성을 띄지 못하게 된다.
따라서, xi_hat이 scale과 shift를 거쳐서 sigmoid 함수의 선형이 아닌 부근에 위치하게 되면 활성화 결과가 비선형을 띌 수 있게 된다.
배치 정규화의 계산 그래프

순전파로 xi가 xi_hat이 되는 과정을 계산 그래프로 나타낸 것이다.
MNIST에의 배치 정규화 적용

MNIST 데이터에 배치 정규화 적용 시 학습 속도가 빨라졌다. 배치 정규화로 학습 속도가 빨라지게 되어 dropout과 같은 규제를 하지 않아도 된다.
가중치 초깃값에 영향받지 않는 배치 정규화

가중치 초깃값에 따라 배치 정규화를 적용했을 때와 적용하지 않았을 때의 학습 속도를 비교하니 가중치 초깃값에 관계 없이 항상 배치 정규화를 적용 했을 때 학습 성능이 좋았다.
6.4 바른 학습을 위해
- overfitting을 억제하는 기술이 필요하다.
Overfitting
- 매개변수가 많을 때 (n↑)
- 학습 데이터가 적을 때 (m↓)
=> 모델 학습 시 train set의 accuracy는 높은데 test set의 accuracy는 낮아지는 문제가 생긴다.
즉, 모델이 범용 데이터에 적용되지 않는다.
Overfitting을 억제하는 방법
(1) 가중치 감소 (weigh decay)
- 가중치가 클 수록 overffiting이 일어나기 쉬움 => 학습 과정에서 큰 가중치에 대해 큰 패널티를 부여하여 overfitting을 억제하는 방법
- 손실함수에 L2 norm (1/2 * λ * W^2)를 더한다.
(2) 드롭 아웃 (Drop Out)
- 뉴런을 무작위로 선택하여 삭제하면서 학습하는 방법

- forward pass를 할 때마다 dropout되는 노드는 임의로 바뀌기 때문에 학습에 큰 영향을 미치는 노드 이외의 다른 노드들에 대해서도 학습이 더 잘 돼서 overfitting이 줄어든다.
- 앙상블의 효과를 볼 수 있다.

- 표현력을 높이면서 overfitting을 막을 수 있다.
6.5 적절한 hyperparameter 값 찾기
- training set: 매개변수 학습
- validation set: hyperparameter 성능 평가: 적절한 hyperparameter 값을 찾기 위해 최적값이 존재하는 범위를 조금씩 줄여 나간다.
- hyperparameter의 대략적인 범위를 설정한다.
- 그 범위 안에서 무작위로 hyperparameter 값을 추출한다.
- train set으로 모델을 학습하고 validation set으로 정확도를 평가한다.
- 이 과정을 반복하여 hyperparameter의 최적값의 범위를 좁혀간다.
- test set: 신경망의 범용성 평가
weight_decay = 10 ** np.random.uniform(-8, -4)
lr = 10 ** np.random.uniform(-6, -2)가중치 감소 범위: 10^(-8) ~ 10^(-4)
학습률 범위: 10^(-6) ~ 10^(-2)

학습이 잘 된 범위의 hyperparameter 값을 기준으로 범위를 좁혀 나간다.
'딥러닝 > 밑바닥부터 배우는 딥러닝' 카테고리의 다른 글
| 7장. 합성곱 신경망(CNN) (0) | 2021.03.02 |
|---|---|
| 5장. 오차역전파법 (1) | 2021.02.10 |
| 4장 신경망 학습 (0) | 2021.02.01 |
| 3장 신경망 (0) | 2021.02.01 |



